
Для поиска и получения информации в сети интернет существуют специальные программы, называемые веб-браузерами. Веб-браузер (Web-browser) это прикладное программное обеспечение для просмотра веб-страниц; содержания веб-документов, компьютерных файлов и их каталогов; управления веб-приложениями; а также для решения других задач. В глобальной сети браузеры используют для запроса, обработки, манипулирования и отображения содержания веб-сайтов. Многие современные браузеры также могут использоваться для обмена файлами с серверами ftp, а также для непосредственного просмотра содержания файлов многих графических форматов (gif, jpeg, png, svg), аудио-видео форматов (mp3, mpeg), текстовых форматов (pdf, djvu) и других файлов.
Функциональные возможности браузеров постоянно расширяются и улучшаются благодаря конкуренции между их разработчиками и высоким темпом развития и внедрения информационных технологий. Большинство современных браузеров придерживается международных стандартов и рекомендаций W3C (World Wide Web Consortium – организация, разрабатывающая и внедряющая технологические стандарты для Всемирной паутины) в области обработки и отображения данных. Стандартизация позволяет добиться предсказуемости в визуальном представлении информации конечному пользователю независимо от технологии, которая использована для ее отображения в браузере.
Google Chrome – браузер, разрабатываемый компанией Google на основе свободного браузера Chromium и движка Blink. По данным StatCounter, Chrome используют около 300 миллионов интернет-пользователей, что делает его самым популярным браузером в мире.
Популярность различных веб-браузеров: StatCounter Global Stats - Browser Market Share
Поисковая система – программно-аппаратный комплекс, предоставляющий возможность поиска информации. Для поиска информации с помощью поисковой системы пользователь формулирует поисковый запрос. По запросу пользователя поисковая система генерирует страницу результатов поиска. Такая поисковая выдача может сочетать различные типы файлов, например: веб-страницы, изображения, аудиофайлы. Некоторые поисковые системы также извлекают данные из баз данных и каталогов ресурсов в Интернете.
В архитектуру поисковой системы включены: поисковый робот, сканирующий сайты сети Интернет, индексатор, обеспечивающий быстрый поиск, и поисковик – графический интерфейс для работы пользователя. Обычно системы работают поэтапно. Сначала поисковый робот получает контент, затем индексатор генерирует доступный для поиска индекс, и наконец, поисковик обеспечивает функциональность для поиска индексируемых данных. Чтобы обновить поисковую систему, этот цикл индексации выполняется повторно. Поисковые системы работают, храня информацию о многих веб-страницах, которые они получают из HTML страниц. Поисковый робот или «краулер» (англ. Crawler) – программа, которая автоматически проходит по всем ссылкам, найденным на странице, и выделяет их. Краулер, основываясь на ссылках или исходя из заранее заданного списка адресов, осуществляет поиск новых документов, ещё не известных поисковой системе. Владелец сайта может исключить определённые страницы при помощи robots.txt, используя который можно запретить индексацию файлов, страниц или каталогов сайта. Поисковая система анализирует содержание каждой страницы для дальнейшего индексирования. Слова могут быть извлечены из заголовков, текста страницы или специальных полей – метатегов. Когда пользователь вводит запрос в поисковую систему (обычно при помощи ключевых слов), система проверяет свой индекс и выдаёт список наиболее подходящих веб-страниц (отсортированный по какому-либо критерию), обычно с краткой аннотацией, содержащей заголовок документа и иногда части текста. Полезность поисковой системы зависит от релевантности найденных ею страниц. Хоть миллионы веб-страниц и могут включать некое слово или фразу, но одни из них могут быть более релевантны, популярны или авторитетны, чем другие. Большинство поисковых систем использует методы ранжирования, чтобы вывести в начало списка «лучшие» результаты.
Google – самая популярная поисковая система в мире Поисковая система Google с момента своего появления всегда следовала принципам простоты и комфорта. Вместо перегруженных рекламой и совершенно лишней информацией поисковых систем конкурентов она представила кристально чистый интефейс, состоящий из одного поля для ввода запроса. Но, несмотря на кажущуюся простоту, поисковая строка Google содержит множество сюрпризов и скрытых возможностей.
Популярность различных поисковых систем: StatCounter Global Stats - Search Engine Market Share
Тремя ключевыми процессами для Google, позволяющими поисковой системе выдавать наиболее соответствующие поисковым запросам результаты, являются следующие: сканирование, индексация и обработка.
Сканирование – это процесс, во время которого роботы Google обнаруживают новые и обновленные страницы для добавления в свою базу. Google использует огромное количество компьютеров, чтобы извлечь (или "просканировать") миллиарды страниц в Интернете. Программа, которая делает выборку, называется «Googlebot» (также известна как робот). Googlebot использует алгоритмический процесс: компьютерные программы определяют какие сайты сканировать и как часто, сколько страниц проиндексировать из каждого сайта. Процесс сканирования Google начинается со списка URL-адресов веб-страниц, полученных от предыдущего сканирования и дополненных данными карты сайта, предоставляемыми вебмастерами. Когда Googlebot посещает каждый из этих сайтов, он обнаруживает ссылки на другие страницы и добавляет их в список страниц, подлежащих сканированию.
Индексация – процесс обработки роботом Google каждой из страниц, на которую он заходит, в целях формирования массивных баз данных из всех слов, которые он распознает и расположения этих слов на каждой из страниц.
Кроме того, Google обрабатывает информацию, расположенную в ключевых тегах и атрибутах, таких как title тегах и атрибутах alt. Обработка происходит в момент, когда пользователь вводит поисковый запрос, тогда поисковая система заходит в свою базу данных (индекс) для подбора наиболее соответствующих запросу страниц и возвращается с результатами, которые являются наиболее соответствующими для пользователей. Соответствие определяется с помощью более, чем 200 факторов, одним из которых является PageRank (PR) данной страницы. PR – это мера важности страницы на основе входящих ссылок с других страниц.
Google – бесспорно очень мощный инструмент для поиска информации. Но как и каждым инструментом, Google нужно уметь пользоваться. Для поиска информации в Google необходимо записать запрос и получить результат. Но иногда на то, чтобы найти нужную информацию уходит очень много времени, так как приходится просмотреть множество сайтов. Для уточнения результатов поиска можно использовать специальные символы и слова. За исключением приведенных ниже примеров, пунктуация при поиске, как правило, игнорируется.
«+» – поиск по нескольким ключевым словам, ставится в запросе автоматически вместо пробелов. Например запись «теплоэнергетические установки» равносильна «теплоэнергетические + установки.»
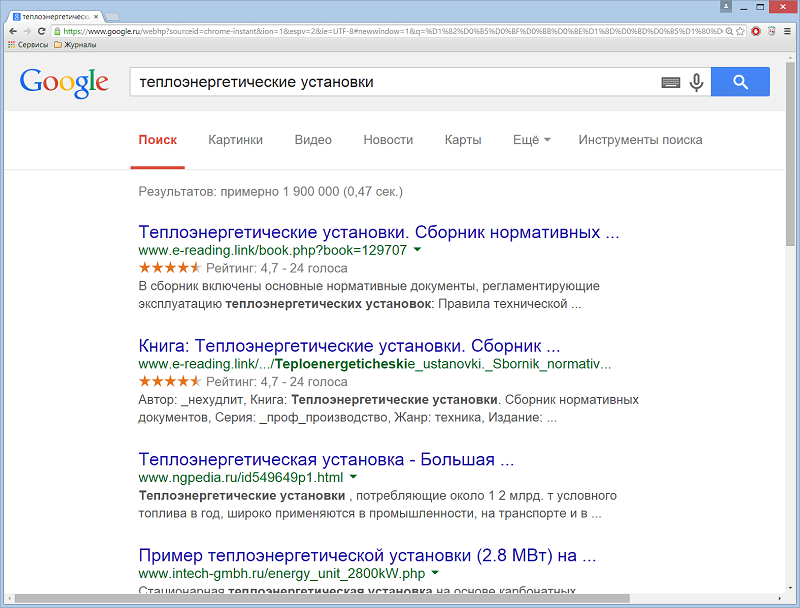
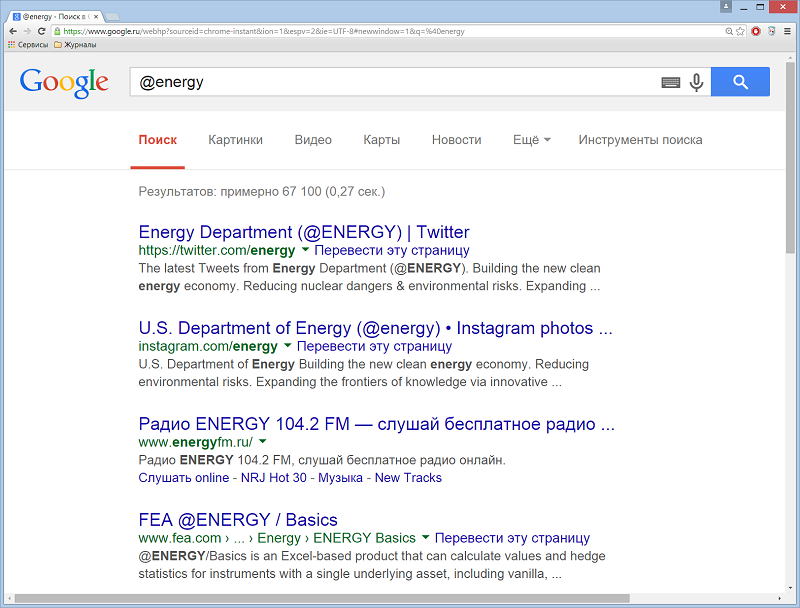
«@» – поиск тегов социальных сетей Пример: @energy.
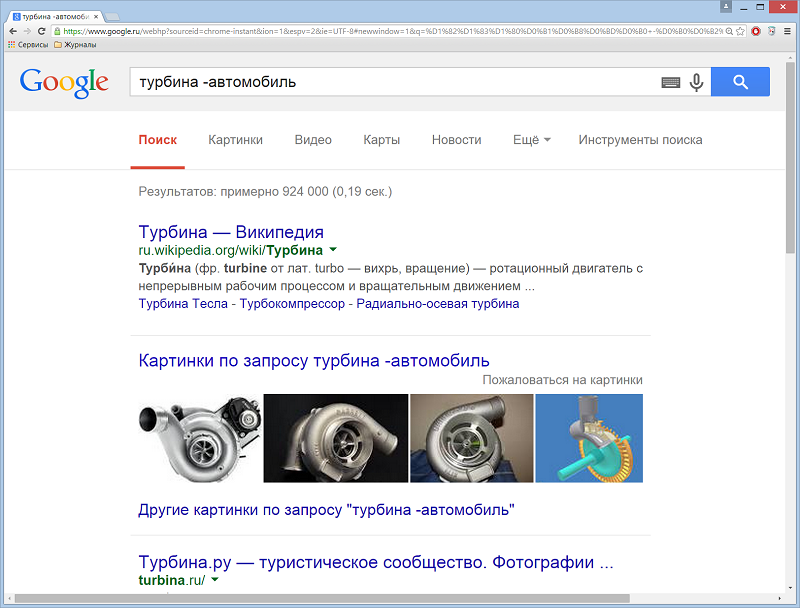
«-» – удаление слов. Если ввести дефис перед словом или адресом сайта, страницы с этим словом или сайтом будут исключены из результатов поиска. Это полезно при поиске слов, которые имеют несколько значений, например «турбина -автомобиль».
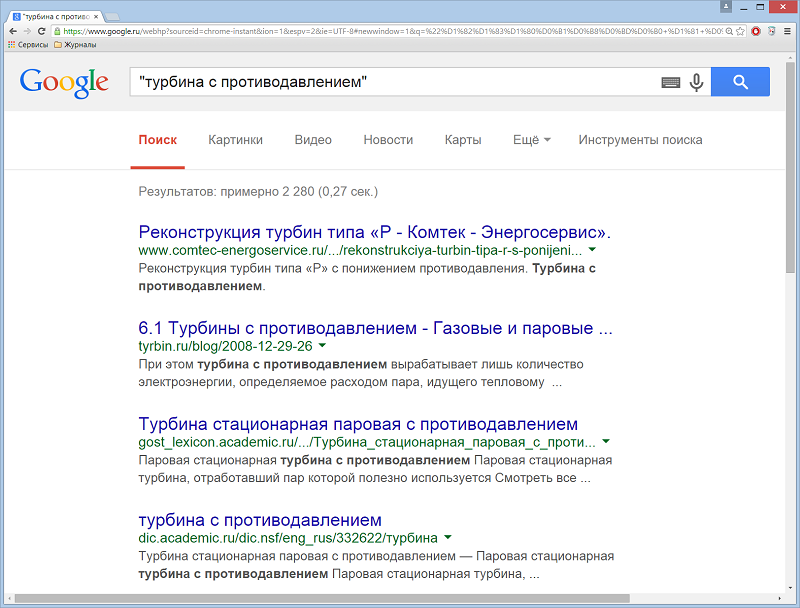
«" "» – если поместить слово или фразу в кавычки, в результатах поиска будут содержаться только страницы с этими словами в том же порядке, в котором они указаны в кавычках. Используется, только если вы ищете точное слово или фразу. Пример: "турбина с противодавлением".
«*» – звездочка заменяет любое слово в запросе. Ее можно использовать в комбинации с кавычками для поиска вариантов фразы. Это удобно, например, когда нужно найти выражение, которое вы не помните точно. Пример: "ГОСТ * Тепловые сети".
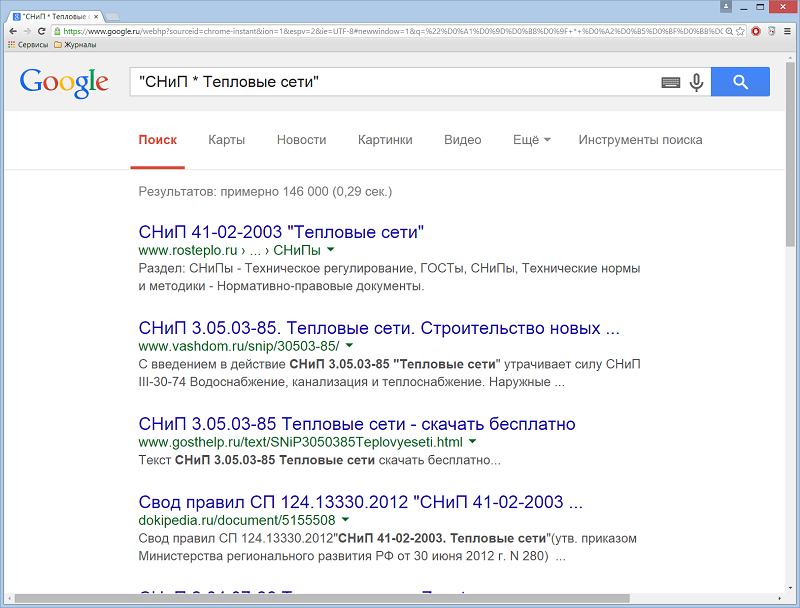
«..» – чтобы получить результаты, содержащие цифры в заданном диапазоне, например в датах, ценах и размерах, необходимо ввести между нужными цифрами две точки без пробела. Пример: "источник питания 430..460 Вт".
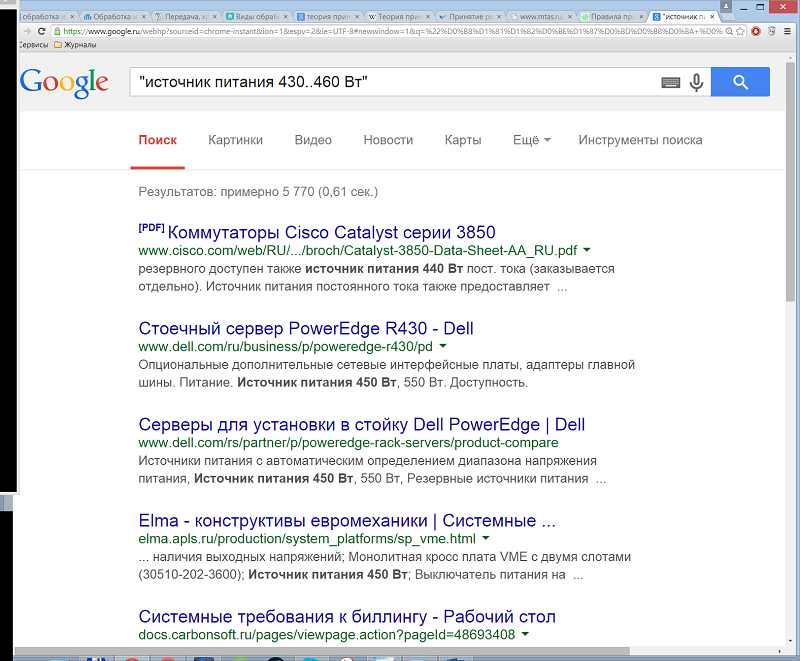
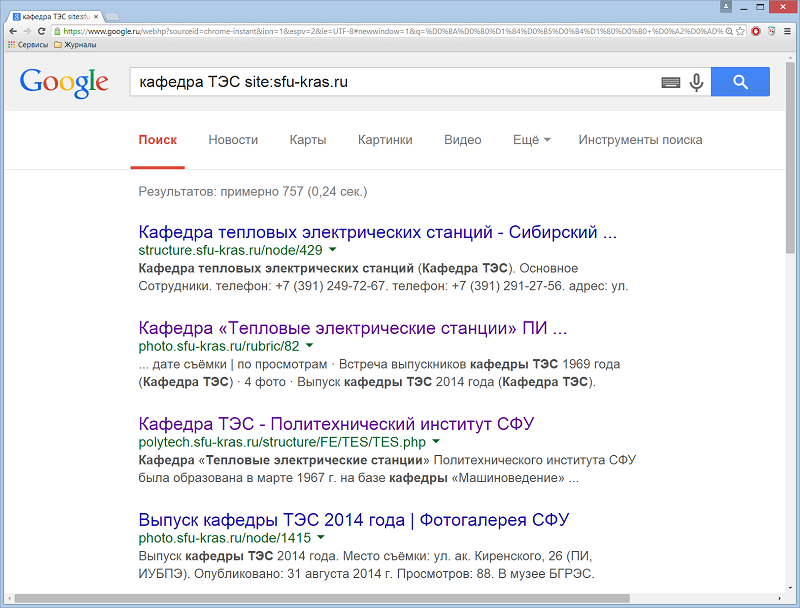
Также для уточнения запроса используют операторы поиска. При поиске с использованием операторов не добавляется пробел между оператором и поисковым запросом. Например, поисковый запрос site:sfu-kras.ru сработает, а запрос site: sfu-kras.ru – нет.
Оператор site: – получение результатов из определенных сайтов или доменов. Например, вы можете найти все упоминания о кафедре на сайте университета или на сайтах в общем домене .com. Примеры: кафедра ТЭС site:sfu-kras.ru.
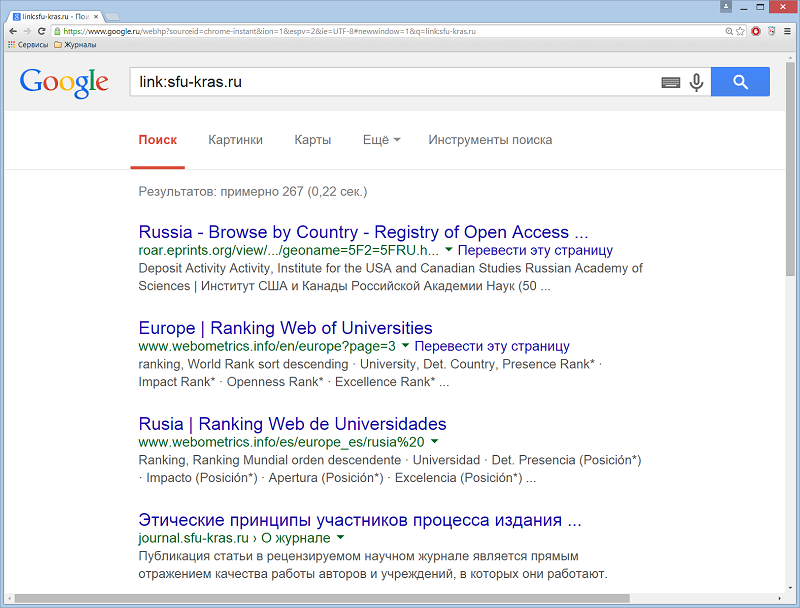
Оператор link: – находит страницы, ссылающиеся на определенный сайт. Например, если вас интересуют все ресурсы со ссылками на sfu-kras.ru, введите запрос: link:sfu-kras.ru.
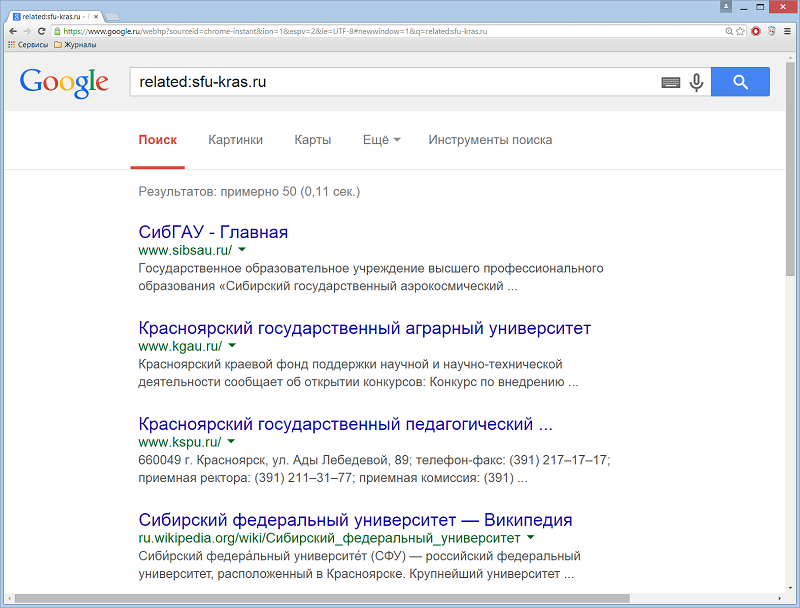
Оператор related: – используется для поиска веб-страниц со схожим содержанием. Если вы ищете сайты, похожие на sfu-kras.ru, в результатах поиска будут показаны другие новостные ресурсы, которые могут вас заинтересовать. Пример: related:sfu-kras.ru.
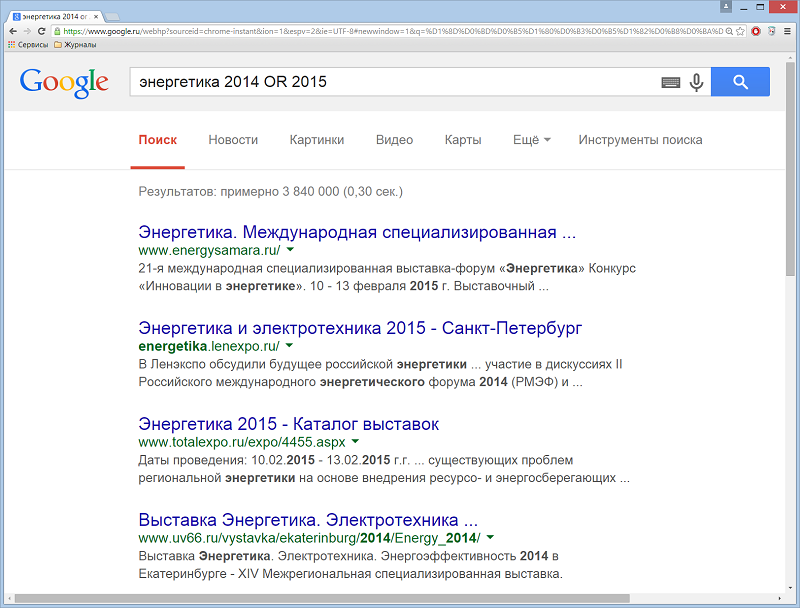
Оператор OR – находит страницы, содержащие как минимум одно из указанных слов. Результаты поиска по запросу без этого оператора будут содержать оба термина. Пример: энергетика 2014 OR 2015.
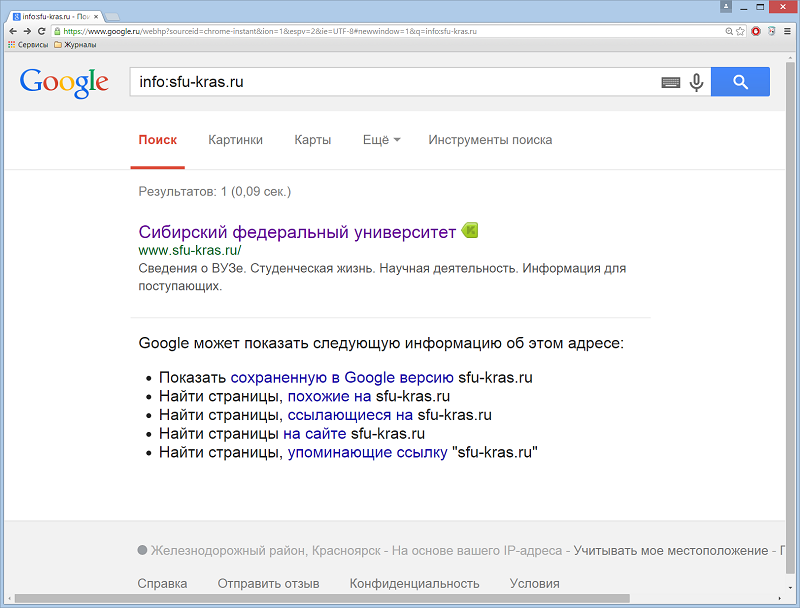
Оператор info: – С помощью этого оператора можно получить сведения об URL, в том числе ссылки на кешированную версию страницы, похожие сайты, а также страницы, ссылающиеся на указанную вами. Пример: info:sfu-kras.ru.
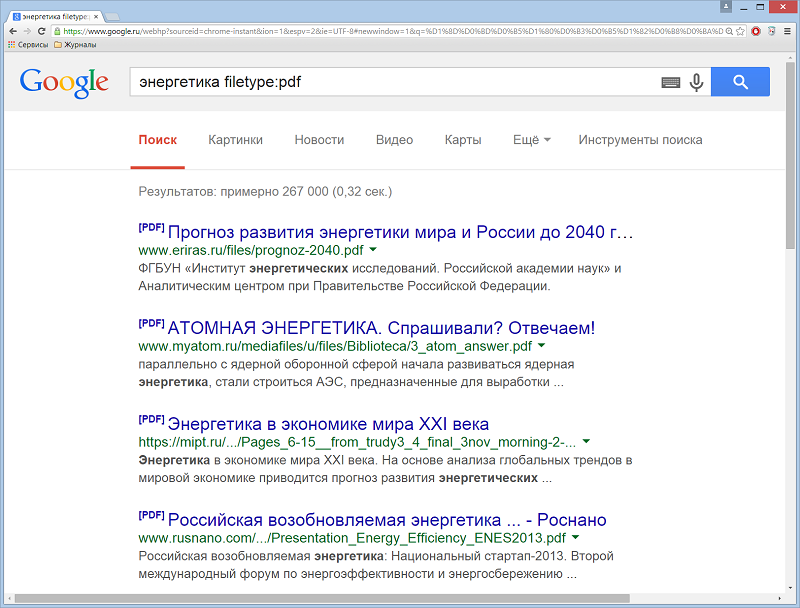
Оператор filetype: – используется для отображения только файлов заданного расширения. Полный список поддерживаемых форматов на момент написания данного текста: Adobe Reader PDF (pdf), Adobe Postscript (ps), Autodesk DWF (dwf), Google Earth (kml, kmz), Microsoft Excel (xls), Microsoft PowerPoint (ppt), Microsoft Word (doc), Rich Text Format (rtf), Shockwave Flash (swf). Например: энергетика filetype:pdf.
Оператор weather:
– используется для отображения прогноза погоды. Например: weather:Красноярск.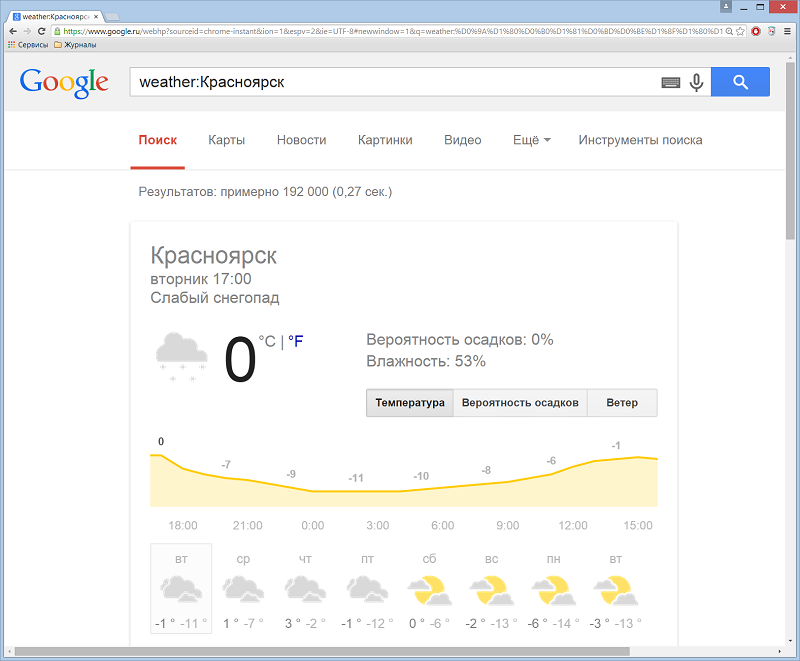
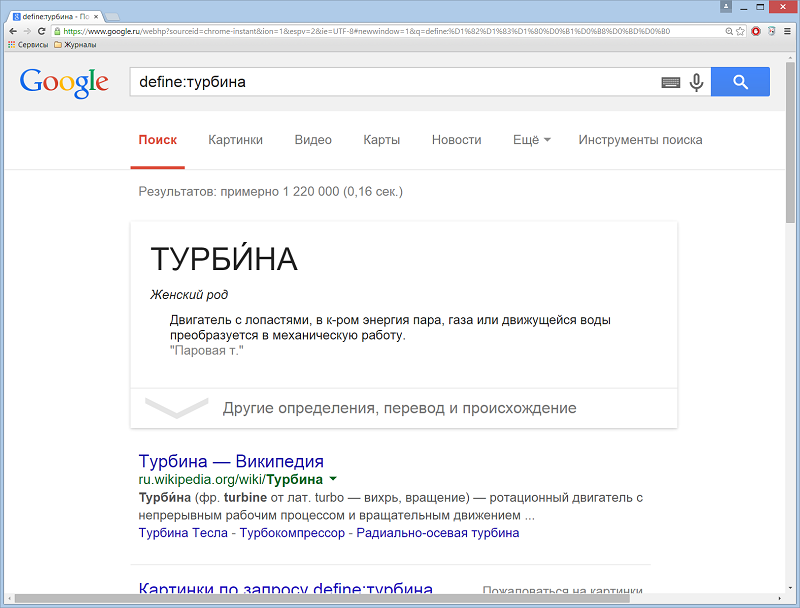
Оператор define: – используется для быстрого поиска определений. Пример: define:турбина.
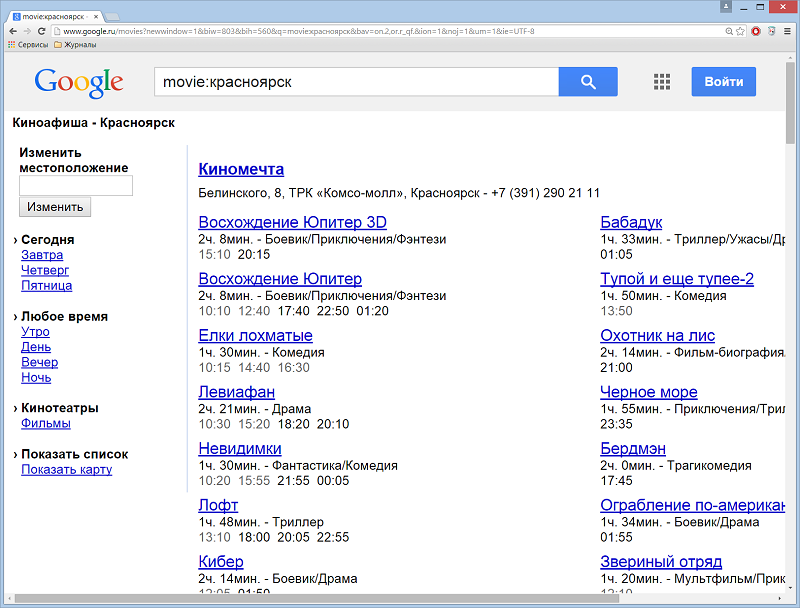
Оператор movie: –используется для отображения списка фильмов, с ссылками на расписание сеансов во всех кинотеатрах. Например: movie:Красноярск.
При поиске устаревших страниц и страниц, контент которых был обновлен, может помочь поиск в кэше поисковой машины. Для этого предназначен оператор cached:. Update: Существует так же близкий по смыслу оператор cache:, с помощью которого можно сразу получать страницы из кэша по их URL. Этой возможностью в принципе можно пользоваться как своеобразным бэкапом видимых для Google веб-страниц: даже если страница будет удалена со своего сайта, на Google может остаться ее копия.
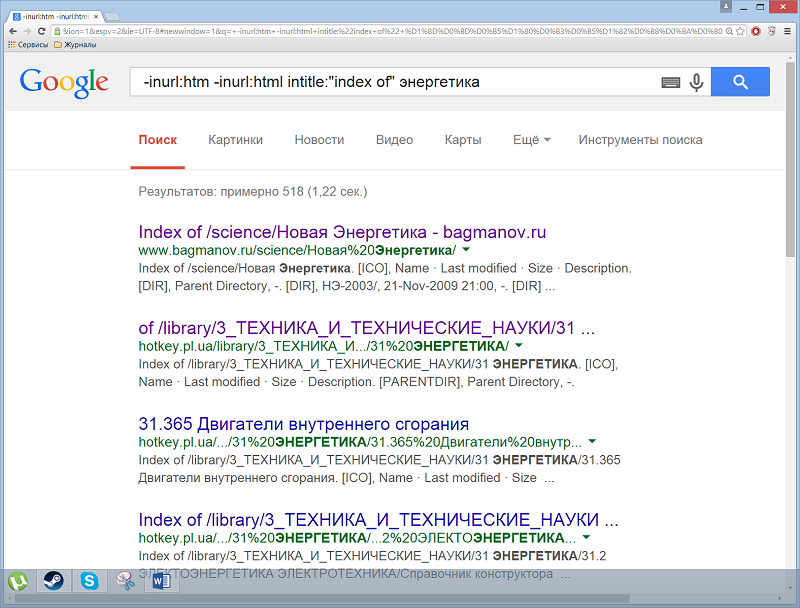
Операторы inurl:, intitle:, inanchor:. По-умолчанию Google ищет заданный текст внутри содержимого страниц. Но если есть необходимость искать в некоей определенной области, можно использовать такие операторы как «inurl:» (поиск внутри URL), «intitle:» (поиск в заголовке страницы), «intext:» (поиск в тексте страницы), и «inanchor:» (поиск в тексте ссылок). Например: -inurl:htm -inurl:html intitle:"index of" энергетика.
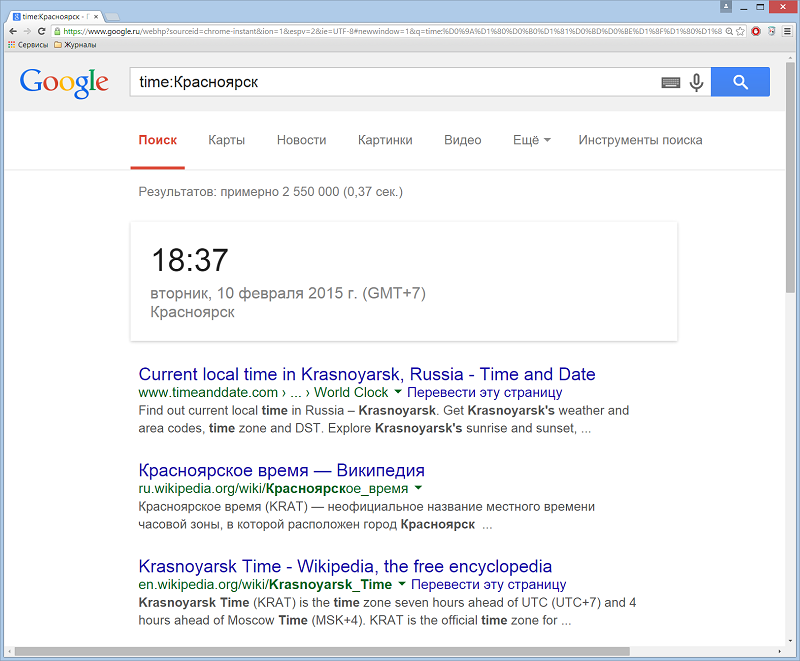
Оператор time: – показывает точное время в любом месте. Например: time:Красноярск.
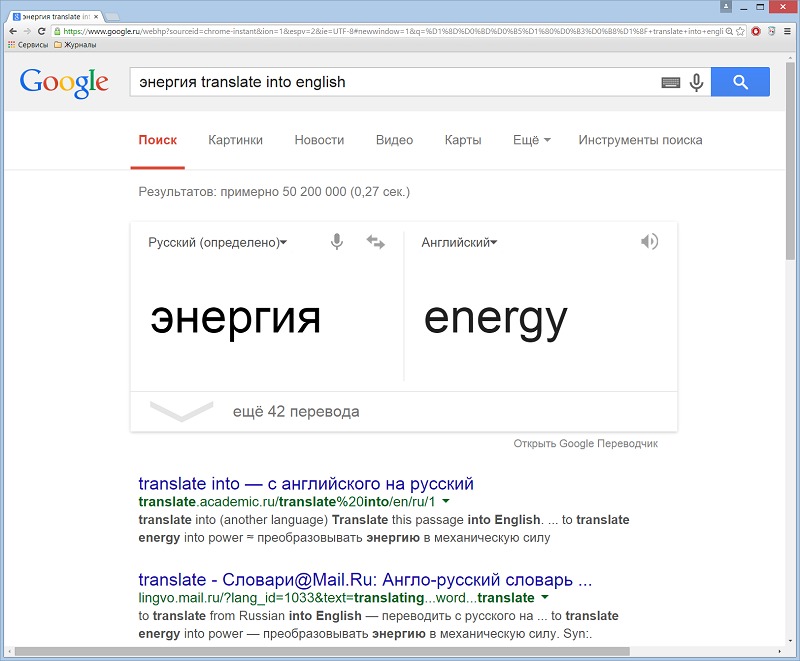
Оператор «translate into» переводит строку запроса из одного языка в другой. Он построен на другой службе Google Переводчик. Google Переводчик (англ. Google Translate) – веб-сервис компании Google, предназначенный для автоматического перевода части текста или веб-страницы на другой язык. Для некоторых языков пользователям предлагаются варианты переводов. Сервис включает в себя также перевод всей веб-страницы и даже одновременный поиск информации с переводом на другой язык.
Например: энергия translate into english.
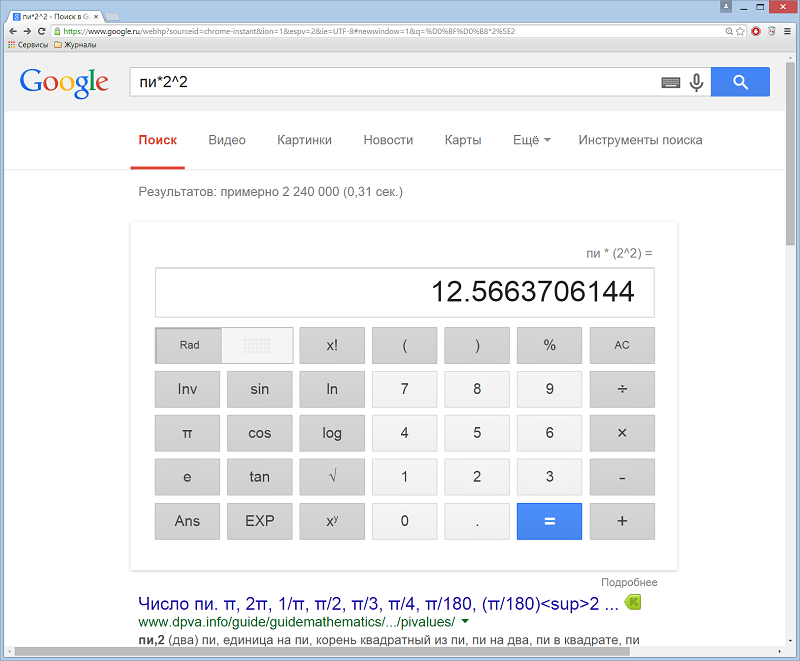
Простейший калькулятор. В Google Поиске можно быстро выполнять вычисления и конвертировать единицы измерения. Просто введите в окне поиска математическое выражение или необходимое преобразование. Калькулятор можно использовать для решения математических задач.
Пример расчета площади круга радиусом 2 м.
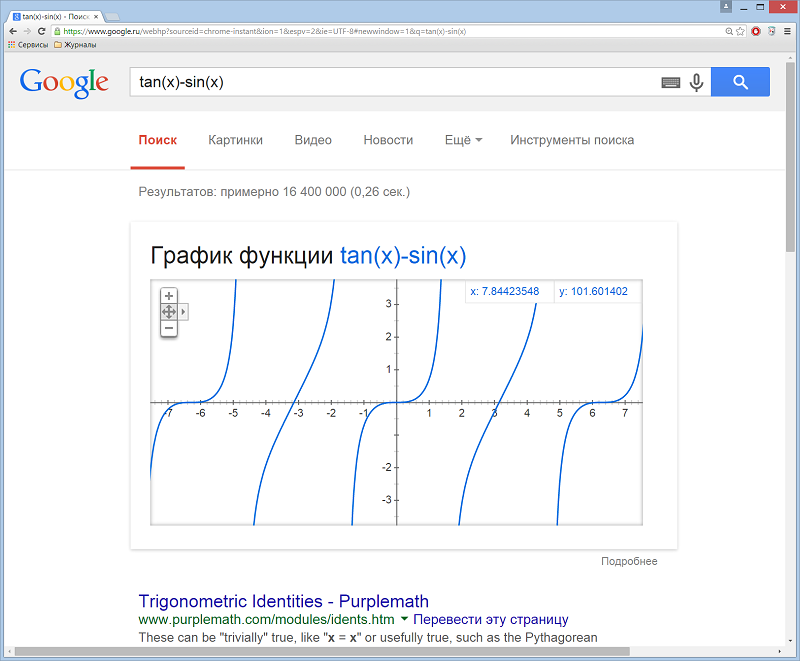
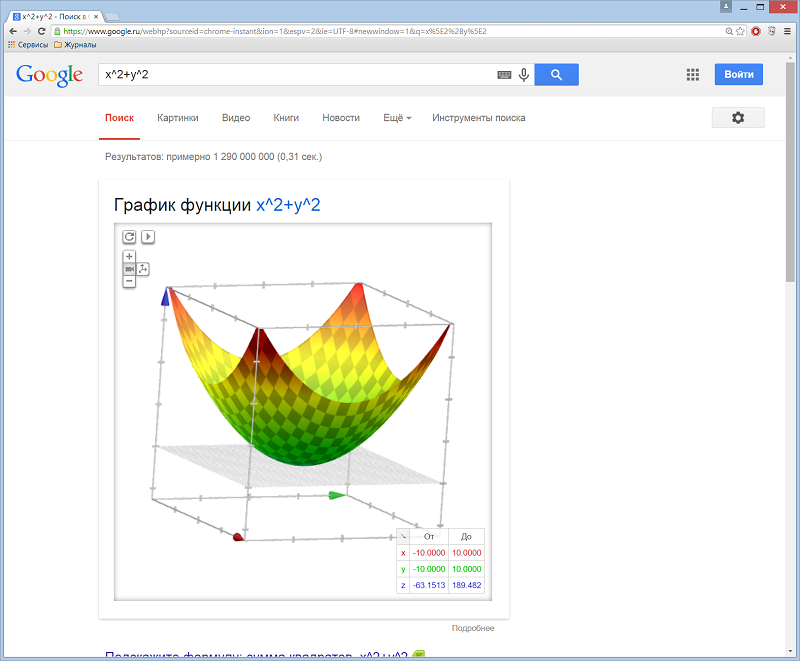
Поисковый интерфейс Google позволяет строить графики функций. Список поддерживаемых функции:
Графики можно исследовать более подробно, приближая, удаляя и перемещая их на плоскости. Если вам нужно построить несколько графиков в одной системе координат, отделите выражения запятой.
Построим графики функций одной переменной tan(x)-sin(x) и многих переменных x^2+y^2.
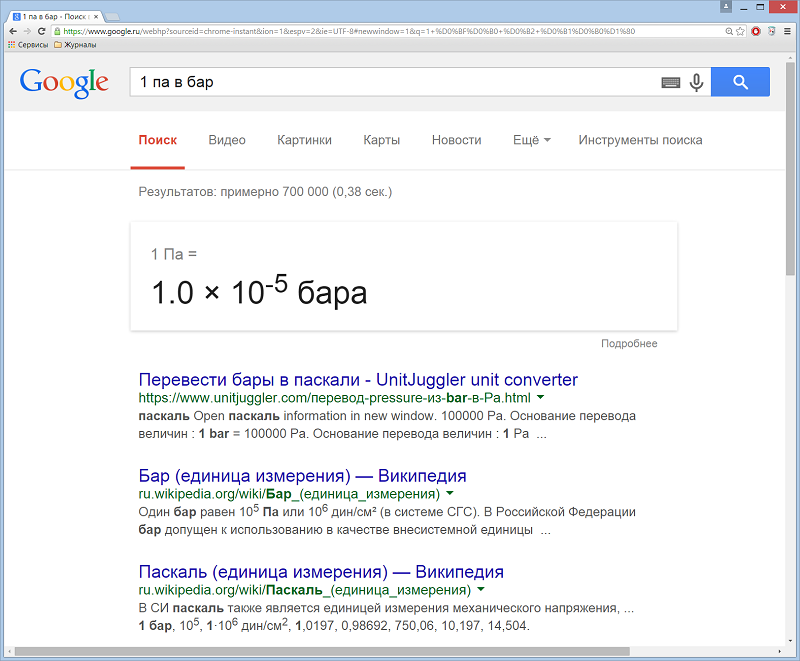
Перевод единиц измерения. С помощью конвертера единиц измерения можно находить соответствие для тех или иных величин в других системах мер. Пример: перевод единиц давления из паскалей в бары.
Существуют информационно-поисковые системы для решения более узких задач. Примерами таких систем могут служить информационно-поисковая система Федерального института промышленной собственности и интегрированная библиотечно-информационная система ИРБИС.
Информационно-поисковая система Федерального института промышленной собственности предназначена для проведения патентного поиска.
Федеральное государственное бюджетное учреждение «Федеральный институт промышленной собственности» создано в результате реорганизации Федерального государственного учреждения «Федеральный институт промышленной собственности Федеральной службы по интеллектуальной собственности, патентам и товарным знакам» и Федерального государственного учреждения «Палата по патентным спорам Федеральной службы по интеллектуальной собственности, патентам и товарным знакам» в форме присоединения второго учреждения к первому в соответствии с распоряжением Правительства Российской Федерации от 01 декабря 2008 г. № 1791-р.
Институт является правопреемником Федерального государственного учреждения "Федеральный институт промышленной собственности Федеральной службы по интеллектуальной собственности, патентам и товарным знакам", ранее именовавшегося Государственным учреждением "Федеральный институт промышленной собственности" (некоммерческая организация), созданного постановлением Правительства Российской Федерации от 19 сентября 1997 г. № 1203 на базе Всероссийского научно-исследовательского института государственной патентной экспертизы, Управления прав промышленной собственности и Производственного предприятия "Патент" путем их слияния и присоединения к нему в качестве структурных подразделений Всероссийской патентно-технической библиотеки и Российского агентства по правовой охране программ для электронных вычислительных машин, баз данных и топологий интегральных микросхем, и Федерального государственного учреждения "Палата по патентным спорам Федеральной службы по интеллектуальной собственности, патентам и товарным знакам", ранее именовавшегося Государственным учреждением "Палата по патентным спорам Российского агентства по патентам и товарным знакам", созданного в результате переименования Государственного учреждения "Апелляционная палата Российского агентства по патентам и товарным знакам" на основании приказа Российского агентства по патентам и товарным знакам от 13.02.2003 № 19.
Полное официальное наименование Института на русском языке: Федеральное государственное бюджетное учреждение «Федеральный институт промышленной собственности»; сокращенные наименования - Федеральный институт промышленной собственности, ФИПС; наименование на английском языке - Federal Institute of Industrial Property.
Адрес сайта информационно-поисковая система Федерального института промышленной собственности http://www1.fips.ru/. В качестве информационных ресурсов представлены:
В разделе «Официальные публикации» публикуются официальные бюллетени Роспатента по объектам интеллектуальной собственности.
В разделе «Международные классификации» представлены Международная Патентная Классификация (МПК); Международная Классификация Промышленных Образцов (МКПО) и Международная Классификация Товаров и Услуг (МКТУ).
В информационно-поисковой системе (ИПС) возможен поиск по изобретениям, рефератам патентных документов на русском и английском языках, перспективным изобретениям, полезным моделям, товарным знакам, общеизвестным товарным знакам, наименованиям мест происхождения товаров, международным товарным знакам с указанием России, промышленным образцам, классификаторам и документам официальных бюллетеней за последний месяц. В БД возможен поиск по текстовым полям, по номерам и по датам с использованием масок, подстановок, интервалов, и т.д.
Бесплатный доступ открыт к текстам МПК, МКТУ, МКПО (без поиска), БД перспективных изобретений (IMPIN), БД рефератов Российских патентных документов на русском (RUPATABRU) и английском (RUPATABEN) языках, БД рефератов полезных моделей (RUPMAB), программ для ЭВМ (SWDB), зарегистрированных баз данных (TEST_DB) и топологий интегральных микросхем (TIMS), полным текстам Российских патентных документов из последнего бюллетеня.
Открытые реестры представляют собой структурированный список документов по номеру регистрации или заявки по определенному объекту промышленной собственности. Пользователям предоставляется доступ к информации о регистрациях с указанием правового статуса или состояния делопроизводства по заявкам.
На портале открыты реестры товарных знаков и знаков обслуживания Российской Федерации, изобретений, полезных моделей и промышленных образцов Российской Федерации, наименований мест происхождения товаров Российской Федерации, общеизвестных в Российской Федерации товарных знаков, международных товарных знаков с указанием Российской Федерации, также доступны открытые реестры по заявкам на регистрацию товарных знаков, знаков обслуживания и наименований мест происхождения товаров (НМПТ) Российской Федерации, по заявкам на выдачу патента Российской Федерации на изобретения, полезные модели и промышленные образцы.
В открытых реестрах предусмотрена возможность просмотра официальной публикации в формате PDF, идентичной публикации в официальных бюллетенях Роспатента.
Для поиска научной литературы в Сибирском Федеральном университете используется библиотечно-информационная система, доступная по адресу http://bik.sfu-kras.ru/. Поиск по системе может производиться по автору, заглавию, году издания и ключевым словам.
Имеется доступ к поисковой системе через единую точку входа к информационным ресурсам библиотек г. Красноярска входящих в ИРБИС, таким как: Электронный каталог Государственной универсальной научной библиотеки Красноярского края, Электронный каталог Центральной научной библиотеки КНЦ СО РАН, Электронный каталог Библиотеки института физики им. Л.В. Киренского СО РАН, Электронный каталог Библиотеки института биофизики СО РАН, Электронный каталог Библиотеки института вычислительного моделирования СО РАН, Электронный каталог Библиотеки Института леса СО РАН, Электронный каталог Библиотеки института химии и химических технологий СО РАН, Электронный каталог Красноярского государственного педагогического университета им. В. П. Астафьева, Электронный каталог Научной библиотеки Сибирского государственного технологического университета.
После нахождения необходимой информации часто возникает необходимость ее обработать, т.е. получить дополнительную информацию используя существующую.
