
Современные информационные системы оперируют огромными потоками данных, которые представляются в виде множества различных форм. Современным специалистам, подготовленным в области новых информационных технологий, необходимо ориентироваться в технологиях и методах работы с большим разнообразием сложных типов данных, представленных в виде обобщенных структур, называемых моделями, т.к. они отражают представление пользователя о данных реального мира.
Данные, хранящиеся в памяти ЭВМ, представляют собой совокупность нулей и едениц (битов). Биты объединяются в последовательности: байты, слова и т.д. Каждому участку оперативной памяти, который может вместить один байт или слово, присваивается порядковый номер (адрес). Какой смысл заключен в данных, какими символами они выражены - буквенными или цифровыми, что означает то или иное число - все это определяется программой обработки. Все данные необходимые для решения практических задач подразделяются на несколько типов, причем понятие тип связывается не только с представлением данных в адресном пространстве, но и со способом их обработки. Любые данные могут быть отнесены к одному из двух типов: основному (простому), форма представления которого определяется архитектурой ЭВМ, или сложному, конструируемому пользователем для решения конкретных задач. Данные простого типа это - символы, числа и т.п. элементы, дальнейшее дробление которых не имеет смысла. Из элементарных данных формируются структуры (сложные типы) данных. Из сложных типов данных можно выделить некоторые структуры:
Такие структуры данных как массив или запись занимают в памяти ЭВМ постоянный объем, поэтому их называют статическими структурами. К статическим структурам относится также множество. Имеется ряд структур, которые могут изменять свою длину - так называемые динамические структуры. К ним относятся дерево, список, ссылка. Важной структурой, для размещения элементов которой требуется нелинейное адресное пространство, является дерево. Существует большое количество структур данных, которые могут быть представлены как деревья. Это, например, классификационные, иерархические, рекурсивные и др. структуры.
Существует большое разнообразие сложных типов данных, но среди них можно выделить несколько наиболее общих. Обобщенные структуры называют также моделями данных, т.к. они отражают представление пользователя о данных реального мира. Любая модель данных должна содержать три компоненты: структура данных - описывает точку зрения пользователя на представление данных; набор допустимых операций, выполняемых на структуре данных; ограничения целостности - механизм поддержания соответствия данных предметной области на основе формально описанных правил. В процессе исторического развития в СУБД использовалось следующие модели данных: иерархическая, сетевая и реляционная.
Одними из основополагающих в концепции баз данных являются обобщенные категории данные и модель данных. Понятие данные в концепции баз данных это набор конкретных значений, параметров, характеризующих объект, условие, ситуацию или любые другие факторы. Данные не обладают определенной структурой, данные становятся информацией тогда, когда пользователь задает им определенную структуру, то есть осознает их смысловое содержание. Поэтому центральным понятием в области баз данных является понятие модели. Модель данных это некоторая абстракция, которая, будучи приложена к конкретным данным, позволяет пользователям и разработчикам трактовать их уже как информацию, то есть сведения, содержащие не только данные, но и взаимосвязь между ними.
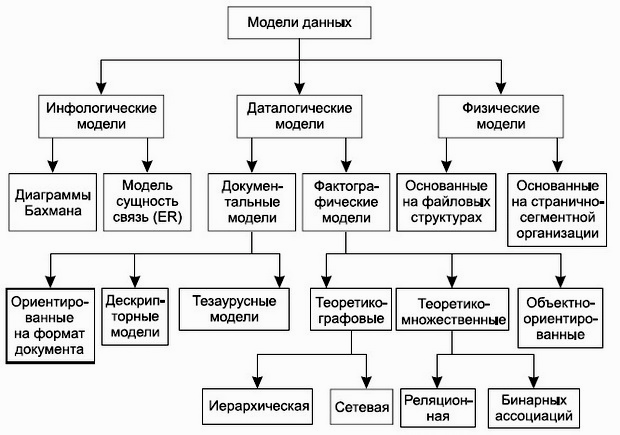
Инфологические модели данных используются на ранних стадиях проектирования для описания структур данных в процессе разработки приложения. Даталогическая модель данных отражает логические взаимосвязи между элементами данных безотносительно их содержания и физической организации. На уровне физической модели электронная база данных представляет собой файл или их набор в формате TXT, CSV, Excel, DBF, XML либо в специализированном формате конкретной системы.
В настоящее время наибольшее практическое применение нашли иерархическая и реляционная модели.
Иерархическая модель данных — логическая модель данных в виде древовидной структуры. Иерархическая модель данных представляет собой совокупность элементов, расположенных в порядке их подчинения от общего к частному и образующих перевернутое дерево (граф). Данная модель характеризуется такими параметрами, как уровни, узлы, связи. Принцип работы модели таков, что несколько узлов более низкого уровня соединяется при помощи связи с одним узлом более высокого уровня. Часто организацию данных в моделях иерархического типа определяется в терминах: элемент, агрегат, запись (группа), групповое отношение, база данных.Корневая запись каждого дерева обязательно должна содержать ключ с уникальным значением. Ключи некорневых записей должны иметь уникальное значение только в рамках группового отношения. Каждая запись идентифицируется полным сцепленным ключом, под которым понимается совокупность ключей всех записей от корневой по иерархическому пути. При графическом изображении групповые отношения изображают дугами ориентированного графа, а типы записей - вершинами (диаграмма Бахмана). Для групповых отношений в иерархической модели обеспечивается автоматический режим включения и фиксированное членство. Это означает, что для запоминания любой некорневой записи в БД должна существовать ее родительская запись (подробнее о режимах включения и исключения записей сказано в параграфе о сетевой модели). При удалении родительской записи автоматически удаляются все подчиненные.
Примерами иерархической модели данных также являются документальные модели данных. Документальные модели данных соответствуют представлению о слабоструктурированной информации, ориентированной в основном на свободные форматы документов, текстов на естественном языке. Модели, основанные на языках разметки документов, связаны прежде всего со стандартным общим языком разметки — SGML (Standart Generalised Markup Language), который был утвержден ISO в качестве стандарта еще в 80-х годах. Этот язык предназначен для создания других языков разметки, он определяет допустимый набор тегов (ссылок), их атрибуты и внутреннюю структуру документа. Контроль за правильностью использования тегов осуществляется при помощи специального набора правил, называемых DTD-описаниями, которые используются программой клиента при разборе документа. Для каждого класса документов определяется свой набор правил, описывающих грамматику соответствующего языка разметки. С помощью SGML можно описывать структурированные данные, организовывать информацию, содержащуюся в документах, представлять эту информацию в некотором стандартизованном формате. Но ввиду некоторой своей сложности SGML использовался в основном для описания синтаксиса других языков (наиболее известным из которых является HTML), и немногие приложения работали с SGML-документами напрямую.
Язык HTML позволяет определять оформление элементов документа и имеет некий ограниченный набор инструкций — тегов, при помощи которых осуществляется процесс разметки. Инструкции HTML в первую очередь предназначены для управления процессом вывода содержимого документа на экране программы-клиента и определяют этим самым способ представления документа, но не его структуру. В качестве элемента гипертекстовой базы данных, описываемой HTML, используется текстовый файл, который может легко передаваться по сети с использованием протокола HTTP. Эта особенность, а также то, что HTML является открытым стандартом и огромное количество пользователей имеет возможность применять возможности этого языка для оформления своих документов, безусловно, повлияли на рост популярности HTML и сделали его сегодня главным механизмом представления информации в Интернете. Ниже приведен пример размещения информации с использованием HTML разметки.
<!DOCTYPE html>
<html>
<head>
<title>Page Title</title>
</head>
<body>
<h1>This is a Heading</h1>
<p>This is a paragraph.</p>
</body>
</html>
XML (Extensible Markup Language) другой язык разметки, описывающий целый класс объектов данных, называемых XML-документами. Он используется в качестве средства для описания грамматики других языков и контроля за правильностью составления документов. Другой популярной реализацией разметки служит JSON. За счёт своей лаконичности по сравнению с XML формат JSON может быть более подходящим для сериализации сложных структур.
Реляционная база данных это набор данных с предопределенными связями между ними. Эти данные организованны в виде набора таблиц, состоящих из столбцов и строк. В таблицах хранится информация об объектах, представленных в базе данных. В каждом столбце таблицы хранится определенный тип данных, в каждой ячейке – значение атрибута. Каждая стока таблицы представляет собой набор связанных значений, относящихся к одному объекту или сущности. Каждая строка в таблице может быть помечена уникальным идентификатором, называемым первичным ключом, а строки из нескольких таблиц могут быть связаны с помощью внешних ключей. К этим данным можно получить доступ многими способами, и при этом реорганизовывать таблицы БД не требуется. Компании всех типов и размеров используют простую, но функциональную реляционную модель для обслуживания разнообразных информационных потребностей. Реляционные базы данных применяются для отслеживания товарных запасов, обработки торговых транзакций через Интернет, управления большими объемами критически важных данных заказчиков и т.д.
Реляционная модель наиболее эффективно поддерживает целостность данных во всех приложениях и копиях (экземплярах) базы данных. Например, когда заказчик кладет деньги на счет с помощью банкомата, а затем проверяет баланс на мобильном телефоне, он ожидает, что поступившие средства сразу же отобразятся на счете. Реляционные базы данных отлично подходят для обеспечения целостности данных в различных экземплярах базы в одно и то же время. Другие типы баз данных не могут одновременно поддерживать целостность больших объемов данных. Некоторые современные типы баз данных, такие как NoSQL, обеспечивают только так называемую “окончательную целостность.” Это значит, что, когда выполняется масштабирование данных или несколько пользователей одновременно используют одни и те же данные, необходимо некоторое время на “внесение изменений”. В некоторых случаях окончательная целостность вполне приемлема (например, для обновления позиций в товарном каталоге), однако для критически важной операционной деятельности бизнеса (например, транзакций с использованием корзины) реляционные базы представляют собой фундаментальный стандарт.
Программное обеспечение, которое используется для сохранения, контроля и извлечения данных в базе, а также выполнения к ней запросов, называют системой управления реляционной базой данных (СУРБД). СУРБД обеспечивает интерфейс между пользователями и приложениями и базой данных, а также административные функции для управления хранением данных, их эффективностью и доступом к ним.
Данные в реляционных структурах организованы в виде набора таблиц, называемых отношениями, состоящих из столбцов и строк. В таблицах хранится информация об объектах, представленных в базе данных. Каждая строка таблицы представляет собой набор связанных значений, относящихся к одному объекту, или сущности. Каждая строка в таблице может быть помечена уникальным идентификатором, называемым первичным ключом, а строки из нескольких таблиц могут быть связаны с помощью внешних ключей.
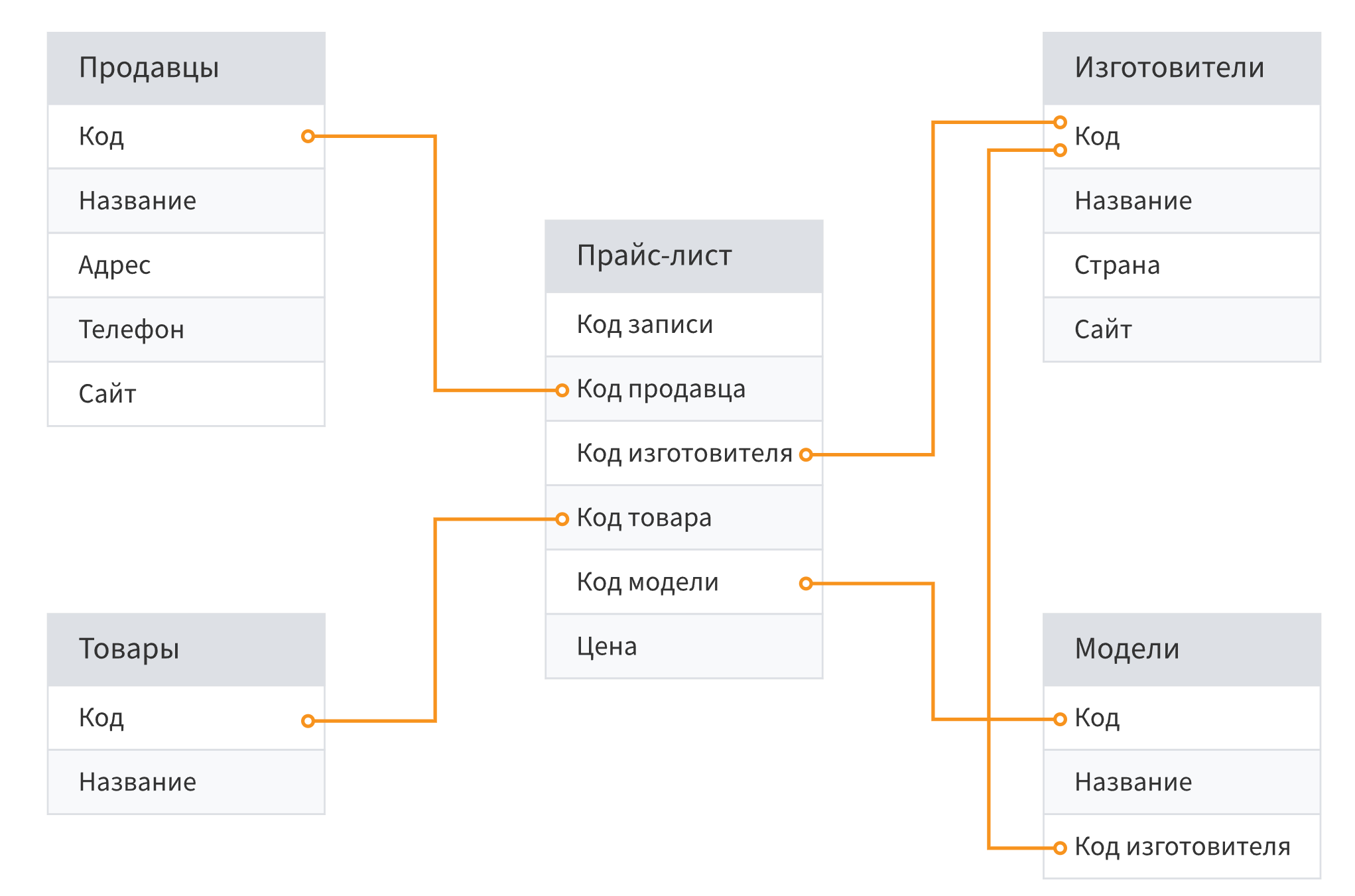
В реляционной базе данных отношения позволяют предотвратить избыточные данные. Например, при разработке базы данных, которая будет отслеживать информацию о книгах, может быть таблица "Названия", в которой хранится информация о каждой книге, например название книги, дата публикации и издатель. Существует также информация, которую вы можете хранить об издателе, например, номер телефона издателя, адрес и почтовый индекс. Если вы храните всю эту информацию в таблице "Названия", номер телефона издателя будет дублироваться для каждого названия, которое печатает издатель. Лучшим решением является хранение информации издателя только один раз, в отдельной таблице, которую мы будем называть "Издатели". Затем вы поместите указатель в таблице "Названия", которая ссылается на запись в таблице "Издатели". Чтобы убедиться, что данные остаются синхронизированными, можно обеспечить целостность данных между таблицами. Отношения целостности данных помогают убедиться, что информация в одной таблице соответствует информации в другой. Например, каждое название в таблице "Названия" должно быть связано с конкретным издателем в таблице "Издатели". Название не может быть добавлено в базу данных для издателя, которого не существует в базе данных. Логические связи в базе данных позволяют эффективно запрашивать данные и создавать отчеты. Всего существует 3 типа связей: Один к одному; Один ко многим; Многие ко многим.
Связь «один-к одному». Когда существует только один экземпляр объекта A для каждого экземпляра объекта B, говорят, что между ними существует связь «один-к одному» (часто обозначается 1:1). Если при проектировании и разработке баз данных у вас нет оснований разделять эти данные, связь 1:1 обычно указывает на то, что в лучше объединить эти таблицы в одну. Но при определенных обстоятельствах целесообразнее создавать таблицы со связями 1:1. Если есть поле с необязательными данными, например «описание», которое не заполнено для многих записей, можно переместить все описания в отдельную таблицу, исключая пустые поля и улучшая производительность базы данных. Чтобы гарантировать, что данные соотносятся правильно, в нужно будет включить, по крайней мере, один идентичный столбец в каждой таблице. Скорее всего, это будет первичный ключ.
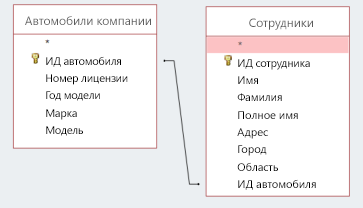
Связь «один-ко-многим». Эта связи возникают, когда запись в одной таблице связана с несколькими записями в другой. Например, один клиент мог разместить много заказов, или у читателя может быть сразу несколько книг, взятых в библиотеке. Чтобы реализовать связь 1:M, добавьте первичный ключ из «одной» таблицы в качестве атрибута в другую таблицу. Если первичный ключ таким образом указан в другой таблице, он называется внешним ключом. Таблица со стороны связи «1» представляет собой родительскую таблицу для дочерней таблицы на другой стороне.
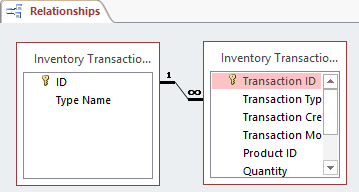
Связь «многие-ко-многим». Когда несколько объектов таблицы могут быть связаны с несколькими объектами другой. Говорят, что они имеют связь «многие-ко-многим» (M:N). Например, в случае студентов и курсов, поскольку студент может посещать много курсов, и каждый курс могут посещать много студентов. При проектировании структуры базы данных реализовать такого рода связи невозможно. Вместо этого нужно разбить их на две связи «один-ко-многим». Для этого нужно создать между этими двумя таблицами новую сущность. Этот вид промежуточного объекта в различных моделях называется таблицей ссылок, ассоциативным объектом или таблицей связей. Каждая запись в таблице связей будет соответствовать двум сущностям из соседних таблиц.
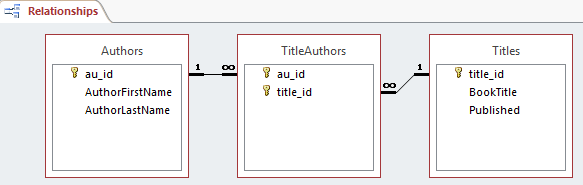
Иногда при проектировании базы данных таблица указывает на себя саму. Например, таблица сотрудников может иметь атрибут «руководитель», который ссылается на другое лицо в этой же таблице. Это называется рекурсивными связями.
Нормализация базы данных. После предварительного проектирования базы данных можно применить правила нормализации, чтобы убедиться, что таблицы структурированы правильно. В то же время не все базы данных необходимо нормализовать. В целом, базы с обработкой транзакций в реальном времени (OLTP), должны быть нормализованы. Базы данных с интерактивной аналитической обработкой (OLAP), позволяющие проще и быстрее выполнять анализ данных, могут быть более эффективными с определенной степенью денормализации. Основным критерием здесь является скорость вычислений. Каждая форма или уровень нормализации включает правила, связанные с нижними формами.
Первая форма нормализации (сокращенно 1NF) гласит, что во время логического проектирования базы данных каждая ячейка в таблице может иметь только одно значение, а не список значений. Таблица с группами повторяющихся или тесно связанных атрибутов не соответствует первой форме нормализации.
Вторая форма нормализации (2NF) предусматривает, что каждый из атрибутов должен полностью зависеть от первичного ключа. Каждый атрибут должен напрямую зависеть от всего первичного ключа, а не косвенно через другой атрибут. Например, атрибут «возраст» зависит от «дня рождения», который, в свою очередь, зависит от «ID студента», имеет частичную функциональную зависимость. Таблица, содержащая эти атрибуты, не будет соответствовать второй форме нормализации.
Третья форма нормализации (3NF): каждый не ключевой столбец должен быть независим от любого другого столбца. Если при проектировании реляционной базы данных изменение значения в одном не ключевом столбце вызывает изменение другого значения, эта таблица не соответствует третьей форме нормализации.
SQL символизирует собой Структурированный Язык Запросов. Это - язык который дает вам возможность создавать и работать в реляционных базах данных. Язык SQL очень прочно влился в бизнес благодаря простоте, удобству и распространенности. Общая структура запроса выглядит следующим образом:
SELECT ('столбцы или * для выбора всех столбцов; обязательно')
FROM ('таблица; обязательно')
WHERE ('условие/фильтрация, например, city = 'Moscow'; необязательно')
GROUP BY ('столбец, по которому хотим сгруппировать данные; необязательно')
HAVING ('условие/фильтрация на уровне сгруппированных данных; необязательно')
ORDER BY ('столбец, по которому хотим отсортировать вывод; необязательно')
Одним из ключевых навыков при работе с базами данных является умение писать sql-запросы. Для новичков рекомендуется интерактивный туториал по изучению SQL.
