
Для любой компании крайне важна бесперебойная работа ее IT-инфраструктуры, особенно серверов и установленного на них программного обеспечения. Прекращение доступа к Интернет, электронной почте, базам данных и другим приложениям неминуемо приведет к серьезным сбоям в бизнес-процессах компании. Для обеспечения стабильной работы приложений серверное оборудование должно отвечать высоким требованиям по надежности. Одним из основных методов повышения надежности сервера является резервирование его подсистем путем дублирования компонентов: процессора, оперативной памяти, сетевых подключений, дисковых и твердотельных накопителей, устройств охлаждения, блоков питания. Отказ дублированного компонента не приводит к отказу сервера в целом, но может снизить его производительность. Устранение неисправности обычно выполняется без остановки работы сервера путем "горячей" замены отказавшего компонента. Надежность сервера определяется параметром MTBF — средним временем наработки на отказ. MTBF сервера можно вычислить теоретически — на основании известных значений MTBF серверных компонентов.
Главными технологиями высокой отказоустойчивости являются отказоустойчивая кластеризация и RAID.
Сегодня RAID (англ. redundant array of independent disks — избыточный массив независимых дисков) применяется повсеместно как основная технология систем хранения в современных центрах обработки данных. Скорее всего, так будет и в обозримом будущем, учитывая развитие облачных вычислений с использованием RAID-технологии и массивными объемами данных, появления которых вызвано феноменом социальных сетей, устройств для смарт-клиентов и мобильного Интернета, распространением видео на потребительских и корпоративных платформах. Внедрение корпорациями решений на основе флэш является следующим логическим шагом, так как разрыв между ростом данных и инвестициями в ИТ-инфраструктуру увеличивается с каждым днем все больше, создавая проблемные «узкие места» (произвоительность или I/O) в критически важных приложениях.

RAID определенно проделал длинный путь с тех пор, как в 1978 году Кен Норман Оучи (Norman Ken Ouchi) из компании IBM получил патент под названием `Система восстановления данных в отказавшем блоке памяти`, который по существу описывает то, что позже станет RAID 5. Спустя девять лет у троих ученых области ИТ из Университета Беркли (Калифорния) возникла идея объединения нескольких жестких дисков в логическую единицу. В 1988 году они опубликовали статью под заголовком `Массивы резервных недорогих дисков`, где доступно описали свою основную цель – решение вопросов потенциальной I/O производительности. По иронии судьбы, технология, которая была ими впервые предложена, широко распространилась за свою способность улучшать функциональную надежность хранения данных в большей степени, чем производительность.
Таким образом впервые концепт RAID был представлен в 1987 году исследователями из университета Беркли Дэвидом Петтерсоном, Гартом Гибсоном и Рэнди Катцем. В июне 1988 года ученые представили доклад «Аргументация в пользу RAID» на конференции SIGMOD. Первыми уровнями спецификации RAID стали RAID 1 (зеркальный дисковый массив), RAID 2 (зарезервированный для массивов, которые применяют код Хемминга), RAID 3 и 4 (дисковые массивы с чередованием и одним выделенным диском четности) и RAID 5 (дисковый массив с чередованием и отсутствием выделенного диска четности).
Кластер из дисков был устроен таким образом, чтобы извне он рассматривался как один диск. Но дешевизна – не главное достоинство RAID, важнее то, что кластер из независимых дисков можно было объединять по различным схемам (по так называемым «уровням» RAID), обеспечивающим большую или меньшую степень сохранности данных за счет избыточности. Поэтому букву I в аббревиатуре стали расшифровывать и как Independent («независимый»). Конфигурации на дисках ATA еще можно считать недорогими, но чаще в корпоративных массивах стоят диски SCSI или Fibre Channel.
Еще одно замечательное качество RAID – многократно большая скорость обмена, она линейно зависит от числа шпинделей. Таким образом, распараллеливание решает проблему «бутылочного горла» на канале диск-компьютер. Но, если просто избыточно увеличивать число дисков, то надежность системы будет уменьшаться.
Данные по дискам распределяются по полосам размером от нескольких килобайтов до нескольких мегабайтов. Вторая процедура для повышения надежности – зеркалирование. Массивы RAID различаются по сочетанию этих процедур. Есть выбор между скоростью доступа и надежностью, возможны и «компромиссные» варианты.
Есть два подхода к реализации RAID: аппаратный и программный. Первый не отнимает ресурсы у процессора, он надежнее, но дороже. Второй тип RAID дешевле.
Спустя годы количество стандартных RAID-схем эволюционировало и получило название `уровни`. RAID 0 увеличил производительность и добавил функцию хранения, при этом была потеряна устойчивость к сбоям. В то время как RAID 1 позволял записывать зеркальные данные одинаково на два диска. RAID 2 и RAID 3 синхронизировали вращение шпинделя диска и сохраняли последовательные биты и байты на паритетный диск. С RAID 4 файлы распространялись между различными дисками, которые выполняли операции независимо, позволяя реагировать на I/O запросы параллельно. Несмотря на то, что все четные данные сохранялись на одном диске, `узкие места` не переставали появляться. RAID 5 распределял четность вместе с данными. В случае сбоя последующие чтения могли быть расчитаны по распределенной четности. RAID 6 обеспечиват отказоустойчивость двух вышедших из строя дисков, делая большие группы RAID более практичными для систем высокой доступности.
Распределение данных на различные устройства в системе RAID может быть внедрено на уровне программного обеспечения или с помощью оборудования. RAID на основе ПО обычно обеспечивается с помощью ОС. ОС серверного класса, которые предлагают менеджмент логических томов, обычно поддерживают RAID и многие операционные системы, обеспечивая базовый функционал RAID. Некоторые продвинутые файловые системы созданы для организации данных на различных устройствах хранения напрямую. ZFS, например, поддерживает все уровни RAID и любые вложенные комбинации.
На уровне оборудования RAID контроллеры могут поддерживать множество операционных систем, так как они представляют RAID как еще один логический накопитель. Они включают кэш чтения/записи, поэтому могут улучшать производительность. Так как чтение/запись энергонезависимы, текущие записи не потеряются в случае сбоя электропитания до тех пор, пока кэш защищается бэкап механизмом. Оборудование RAID предоставляет гарантированную производительность и не добавляет дополнительные вычисления хост-компьютеру, но так как контроллеры используют формат собственных данных, работа с контроллерами различных поставщиков становится невозможной.
Рост популярности гибридных томов. В широком смысле гибридный том – это любой том, где одновременно используются и традиционные жесткие диски (HDD), и твердотельные SSD. В силу этого такое решение, как SSD-кэширование, тоже является одним из вариантов реализации гибридного тома. В RAID-контроллерах Adaptec функция «гибридный том» (Hybrid Volume) подразумевает специальный режим для томов RAID1, 10, где используются как HDD-, так и SSD-диски. Сам рост популярности гибридных томов объясняется довольно просто. SSD-диски в чистом виде не находят широкого применения, поскольку ряд их серверных свойств пока находится в разработке. Цена SSD-дисков довольно высока. Но в то же время SSD-решения обладают уникальной производительностью. Гибридные тома позволяют добавить надежности и емкости со стороны HDD-дисков, производительности со стороны SSD-дисков и оптимизировать цену такого решения.
RAID 0. По другому называется Striping (страйпинг). Для организации такой схемы хранения необходимо как минимум 2 диска одинакового объема. Особенностью RAID-0 является возможность получить виртуальный том большего размера, чем составные диски. Принцип записи данных на диски - последовательное чередование дисков блоками данных одинаковой длинны (Stripe Unit). При этом первая часть данных записывается на первый диск, вторая - на второй и так далее, пока не закончатся физические носители (первая строка записи). После этого запись следует на первый носитель, но на следующий блок данных этого носителя, затем на второй блок второго носителя и так далее(последующие строки). Недостатком такой организации хранения данных является отсутствие дублирования, что при выходе из строя хотя бы одного носителя приводит к полной потере данных. Однако, такой тип организации данных при правильном подборе размера Stripe Unit позволяет получить бОльшую производительность виртуального тома, чем единичного физического носителя.
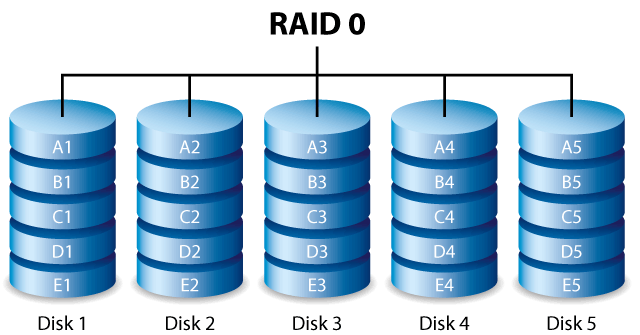
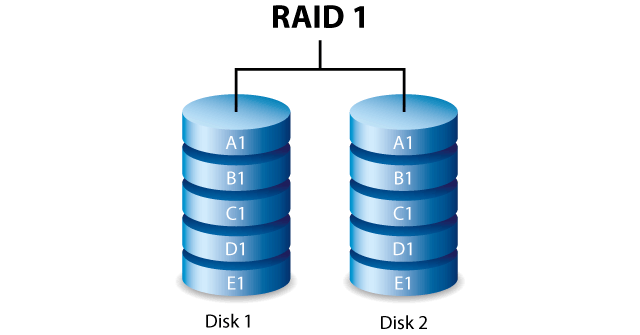
RAID 1. Или зеркалирование (Mirroring). Для организации такой схемы хранения необходимо как минимум 2 диска одинакового объема.При зеркалировании блоки данных записываются одновременно на два или более физичеких устройства. При зеркалировании виртуальный том содержит две и более копий данных. RAID-1 помогает при выходе из строя одного или более носителей, однако обладает существенным недостатком: при такой организации хранения данных требуется большое количество избыточных физических носителей (в 2 раза больше, как минимум).
RAID 4. Чередование с записью контрольной суммы. Для организации такой схемы хранения необходимо как минимум 3 диска одинакового объема. При организации виртуального тома типа RAID-4 данные записываются на физические носители так, как это делается в случае с RAID-0. Однако на последний том записывается контрольная сумма, которая вычисляется с помощью простейшего алгоритма CEC из предыдущих блоков той же строки. При выходе из строя одного из дисков данные могут быть восстановлены используя избыточный диск с контрольными суммами. Недостатком такой организации хранения данных является "горячая точка" - последний диск, хранящий контрольные суммы, так как любая операция записи потребует операцию чтения контрольной суммы, ее перерасчет и запись.
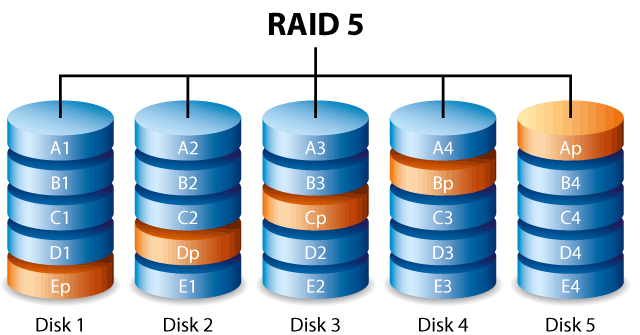
RAID 5. Запись данных с чередованием контрольной суммы. При организации виртуального тома RAID-5 первая строка данных записывается чередованием, как в случае RAID-4, однако далее следуют различия. Вторая строка данных использует предпоследний диск для хранения контрольных сумм и так далее. После перебора всех носителей контрольная сумма опять записывается на последний диск и цикл повторяется. Таким образом RAID-5 позволяет "размазать" горячую точку, контрольную сумму, по всем физическим носителям и устраняет недостаток, присущий RAID-4. RAID 4 и RAID 5 позволяют защитить виртуальный том от выхода из строя одного физического носителя.
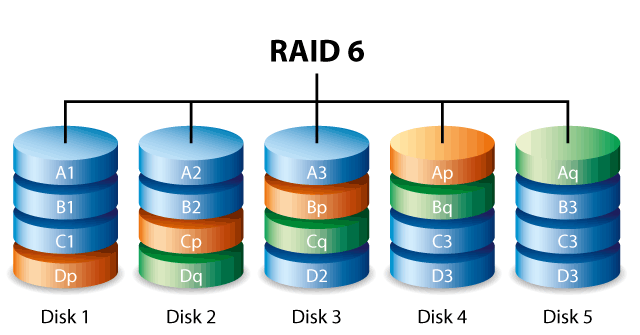
RAID 6. Так же известен как Advanced Data Guarding (ADG). Организация записи аналогична RAID-5 за исключением того, что контрольная сумма записывается в двух экземплярах на различных дисках. Минимальное количество дисков для организации массива – 4. RAID-6 позволяет защитить виртуальный том от выхода из строя до двух физических носителей.
Так же возможна комбинация различных уровней RAID, например:
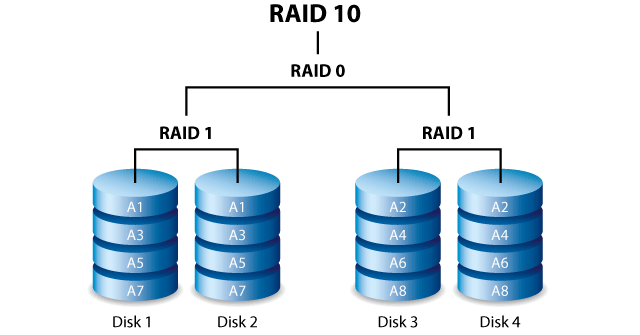
RAID-0+1. Для организации такой схемы хранения необходимо как минимум 4 физических носителя, общее количество носителей должно быть четным. Носители группируются на 2 группы одинакового размера, в каждой группе организуется RAID-0. После этого группы зеркалируются относительно друг-друга.
RAID-1+0. Так же как и в случае RAID-0+1 потребуется минимум 4 физичеких носителя, общее количество носителей должно быть четным. Носители так же группируются парами, между которыми организуется зеркало (RAID-1), после этого между двумя зеркалами организуется страйпинг (RAID-0).
RAID 7.3. Изначально RAID был исключительно аппаратной технологией. Физический RAID-контроллер способен поддерживать несколько массивов различных уровней одновременно, однако более эффективная реализация RAID возможна с помощью программных компонентов (драйверов). Так, ядро Linux позволяет гибко управлять RAID-устройствами. Взяв за основу модули ядра Linux и технологии помехоустойчивого кодирования, разработчики программной технологии RAIDIX сумели создать решение для построения высокопроизводительных отказоустойчивых системы хранения данных на базе стандартных комплектующих. RAID 7.3 является аналогом RAID 6 с двойной четностью, но имеет более высокую степень надёжности. RAID 7.3 – уровень чередования блоков с тройным распределением четности, который позволяет восстанавливать данные при отказе до трех дисков в массиве и достигать высоких скоростных показателей без дополнительной нагрузки на процессор. RAID 7.3 существенно снижает вероятность отказа дисков без потерь в производительности и стоимости и зачастую используется для крупных массивов объемом более 32 ТБ.
RAID N+M. Другая патентованная технология RAID N+M – это уровень чередования блоков с произвольным распределением четности, позволяющий пользователю самостоятельно определить количество дисков, выделяемых под хранение контрольных сумм. Этот уникальный алгоритм позволяет восстановить данные при отказе до 32 дисков (в зависимости от количества дисков четности).
Системы резервного копирования обеспечивают непрерывность бизнес-процессов и защиту информации от природных и техногенных катастроф, действий злоумышленников. Эти технологии активно используются в ИТ-инфраструктурах организаций самых разных отраслей и масштабов.
Резервное копирование данных — процесс создания копии данных на носителе, предназначенном для восстановления данных в оригинальном месте их расположения в случае их повреждения или разрушения. Кроме того, система резервного копирования — это один из необходимых методов обеспечения непрерывности бизнеса. Построение централизованной системы резервного копирования позволяет сократить совокупную стоимость владения ИТ-инфраструктурой благодаря оптимальному использованию устройств резервного копирования и сокращению расходов на администрирование (по сравнению с децентрализованной системой).
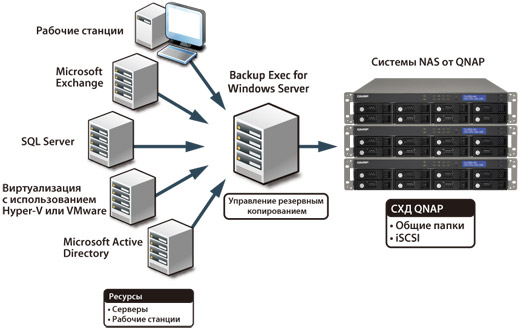
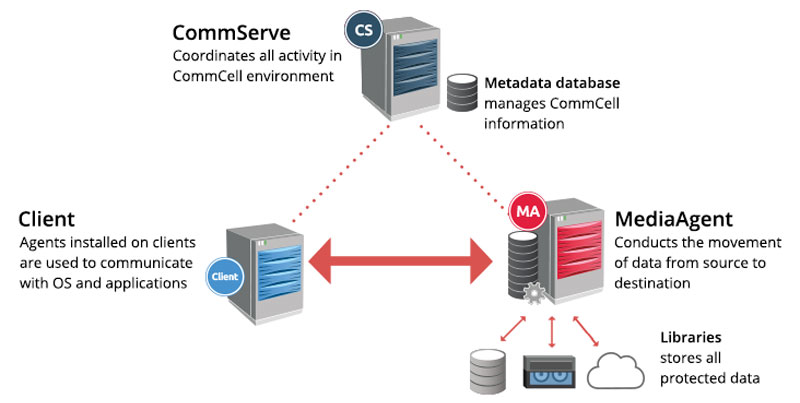
Архитектура и работа системы резервного копирования. Централизованная система резервного копирования имеет многоуровневую архитектуру, в которую входят:
Администратор системы ведет список компьютеров-клиентов резервного копирования, устройств записи и носителей хранения резервных данных, а также составляет расписание резервного копирования. Вся эта информация содержится в специальной базе, которая хранится на сервере управления резервным копированием. В соответствии с расписанием или по команде оператора сервер управления дает команду программе-агенту, установленной на компьютере-клиенте, начать резервное копирование данных в соответствии с выбранной политикой. Программа-агент собирает и передает данные, подлежащие резервированию, на сервер копирования, указанный ей сервером управления.
Сервер копирования сохраняет полученные данные на подключенное к нему устройство хранения данных. Информация о процессе (какие файлы копировались, на какие носители осуществлялось копирование и т. п.) сохраняется в базе сервера управления. Эта информация позволяет найти местоположение сохраненных данных при необходимости их восстановления на компьютере-клиенте. Чтобы система резервного копирования сохраняла непротиворечивые данные компьютера-клиента, они не должны подвергаться изменениям в процессе их сбора и копирования программой-агентом. Для этого приложения компьютера-клиента должны завершить все транзакции, сохранить содержимое кэш-памяти на диск и приостановить свою работу. Этот процесс инициируется по команде программы-агента, которая передается приложениям компьютера-клиента.
Поскольку система резервного копирования предназначена для восстановления данных после сбоя или аварии, созданные резервные копии необходимо проверять на предмет целостности и работоспособности. Кроме того, при построении системы резервного копирования необходимо уложиться в сокращенное «окно» резервного копирования. Вообще говоря, требование круглосуточной работы информационных систем сокращает практически до нуля доступный временной интервал остановки приложений, необходимый для осуществления операции резервного копирования («окно» резервного копирования).
Классификация резервного копирования
Технологии резервного копирования. От ошибок, в результате которых изменяются или удаляются данные и в которых виноваты операционная система или человек, не защищают ни RAID, ни кластер, ни любая другая технология обеспечения отказоустойчивости. Резервное копирование — одно из оптимальных решений для таких ситуаций, так как оно позволяет хранить копии разного срока давности, например за каждый день текущей недели, двухнедельной, месячной, полугодовой и годовой давности. Возможность использовать внешние съемные носители существенно снижает затраты на хранение информации, однако для некоторых задач больше подходят альтернативные технологии.
Резервное копирование с использованием SAN. Применение Сеть хранения данных SAN позволяет полностью перенести трафик резервного копирования с локальной сети на сеть хранения. Существует два варианта реализации: без загрузки локальной сети, или внесетевое копирование (LAN-free backup), и без участия сервера, или внесерверное копирование (Server-free backup).
Внесетевое копирование. При внесетевом копировании данные с диска на ленту и обратно передаются внутри SAN. Исключение сетевого сегмента из пути резервного копирования данных позволяет избежать излишних задержек на передачу трафика через сеть IP и платы ввода-вывода. Нагрузка локальной сети падает, и резервное копирование можно проводить практически в любое время суток. Однако пересылку данных выполняет сервер, подключенный к SAN, что увеличивает нагрузку на него. Благодаря протоколу Fibre Channel с помощью одного оптического кабеля может быть организовано несколько каналов передачи данных. При этом весь объем резервируемых данных с backup-серверов хранения направляется на ленточное устройство, минуя локальную сеть. В этом случае локальная сеть необходима лишь для контроля работы самих backup-серверов со стороны главных серверов. Таким образом, только небольшой объем метаданных, которые содержат информацию о резервируемых данных, передается по локальной сети. Главные серверы отвечают в целом за политику резервного копирования данных в своем сегменте или зоне ответственности. Все backup-серверы по отношению к главному серверу являются клиентами. Считается, что рассматриваемый метод резервного копирования может максимально задействовать пиковую полосу пропускания Fibre Channel. В качестве протокола, применяемого для передачи данных между серверами и библиотеками, могут использоваться как SCSI поверх Fibre Channel, так и IP поверх Fibre Channel, тем более что большинство FC-адаптеров и FC-концентраторов работают одновременно с обоими протоколами (IP и SCSI) на одном Fibre Channel-канале.
Внесерверное копирование. Данный тип резервного копирования представляет собой дальнейшее развитие метода внесетевого копирования (LAN-free), поскольку уменьшает количество процессоров, памяти, устройств ввода-вывода, задействованных в этом процессе. Данный процесс архивирует разделы целиком, в отличие от пофайлового архивирования, но при этом позволяет восстанавливать отдельные файлы. По определению, при вне-серверном копировании данные копируются с диска на ленту и обратно без прямого участия сервера. Поскольку для резервного копирования требуется наличие некоторого дополнительного третьего узла, полностью отвечающего за процесс копирования, то отсюда происходит и другое название этого подхода — копирование с участием третьей стороны (Third_-Party Copy, 3PC). Так, в качестве подобного оборудования может использоваться маршрутизатор хранилищ данных, который берет на себя функции, ранее выполнявшиеся сервером.
Одно из преимуществ архитектуры SAN — отсутствие жесткой привязки составляющих ее систем к каким-либо устройствам хранения данных. Это свойство и заложено в основу технологии резервного копирования без участия сервера. В данном случае к дисковому массиву может иметь прямой доступ как сервер данных, так и устройства, принимающие участие в копировании с дисковых массивов. Резервному копированию блоков данных, относящихся к какому-либо файлу, предшествует создание некоего индекса или списка номеров принадлежащих ему блоков. Это и позволяет в дальнейшем привлечь внешние устройства для резервного копирования.
Таким образом, внесерверное копирование позволяет напрямую перемещать данные между подключенными к сети SAN дисковыми массивами и библиотеками. При этом данные перемещаются по сети SAN и не загружают ни локальную сеть, ни серверы. Такое копирование считается идеальным для корпоративных сетей, которые должны функционировать в непрерывном режиме 24 часа в сутки, 7 дней в неделю. Особенно для тех, для которых временной период, в течение которого можно выполнять резервное копирование без существенного влияния на работу пользователей и приложений, становится недопустимо малым.
Репликация данных. Современные дисковые массивы обладают средствами создания копий данных внутри самого массива. Данные, созданные этими средствами, носят название Point-In-Time (PIT)-копий, т.е. фиксированных на определенный момент времени. Существует две разновидности средств создания PIT-копий: клонирование и «моментальный снимок» (snapshot). Под клонированием обычно понимают полное копирование данных. Для него требуется столько же дискового пространства, как и для исходных данных, и некоторое время. При использовании такой копии нет нагрузки на дисковые тома, содержащие исходные данные. Иными словами, нет дополнительной нагрузки на дисковую подсистему продуктивного сервера.
Механизм работы «моментальных снимков» иной и может быть реализован как программно на продуктивном сервере, так и аппаратно внутри массива. В момент, когда необходимо начать резервное копирование, программа-агент дает команду приложению завершить все транзакции и сохранить кэш-память на диск. Затем создается виртуальная структура — snapshot, представляющая собой карту расположения блоков данных, которую ОС и другое ПО воспринимает как логический том. Приложение прерывает стандартный режим работы на короткое время, необходимое для сохранения данных. После этого приложение продолжает работать в стандартном режиме и изменять блоки данных, при этом перед изменением старые данные блока с помощью драйвера snapshot копируются в область кэш-памяти snapshot и в карте расположения блоков данных указывается ссылка на новое местоположение блока. Таким образом, карта snapshot всегда указывает на блоки данных, полученные на момент завершения транзакций приложением. Блоки данных, которые не были изменены, хранятся на прежнем месте, а старые данные измененных блоков — в области кэш-памяти snapshot. Программа-агент копирует непротиворечивые данные, полученные на момент завершения транзакций приложением, осуществляя доступ к ним через драйвер snapshot, т. е. используя карту расположения блоков. Создание копий с помощью «моментальных снимков» экономит дисковое пространство, но создает дополнительную нагрузку на дисковую подсистему продуктивного сервера. Какой из методов создания PIT-копий выбрать, решается на этапе проектирования системы резервного копирования, исходя из бизнес-требований, предъявляемых к системе.
Другой важной задачей обеспечения высокой отказоустойчивости являются системы бесперебойного электропитания сервера и серверного оборудования в офисе на продолжительное время, а так же для защиты персональных компьютеров от внезапных пропаданий электроэнергии.
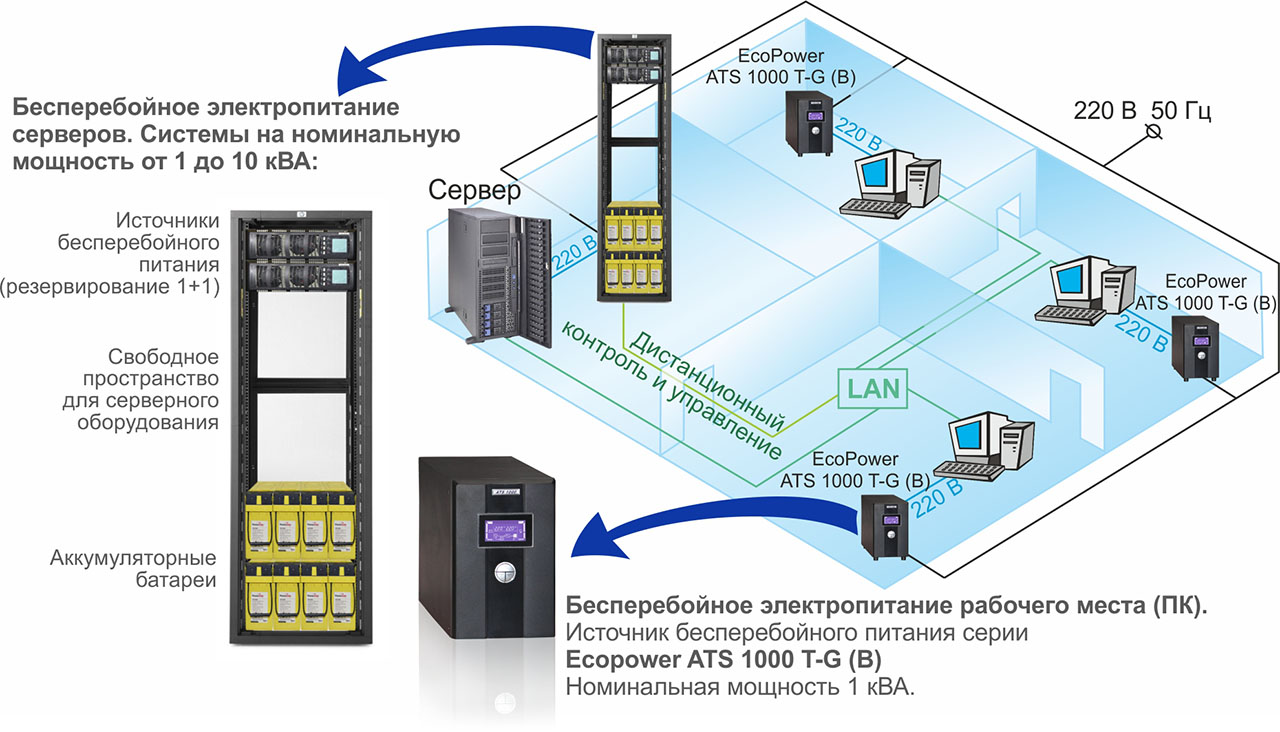
Резервное (гарантированное) питание — это электропитание, при котором система или отдельный ее узел постоянно питаются от основного источника , а подключение резервного источника происходит лишь при пропадании напряжения в основной питающей цепи.
Бесперебойное питание — это электропитание, при котором источник одновременно выполняет функции и основного, и резервного. При пропадании напряжения в основной цепи источник бесперебойного питания автоматически переходит на резервное питание.
В общем случае, в технической литературе все источники с функцией резерва можно называть «источниками вторичного электропитания резервированные (ИВЭПР)». Для таких источников приняты так же названия: ББП (блок бесперебойного питания), БРП (блок резервированного питания) , РИП (резервированный источник питания), ИВП (источник вторичного питания). При этом термины «ИВЭПР», «РИП», «ИБП» чаще используют специалисты по построению ОПС, систем контроля доступа и систем безопасности. Термины «ББП», «БРП» обычно используются при построении систем связи, коммуникационных узлов, в системах домофонов и в системах оповещения. Источники бесперебойного питания для систем наблюдения CCTV обычно называются «ИБП», «ИВЭПР», «РИП». Автономные ИБП (источники бесперебойного питания), ИВЭПР ( источники вторичного электропитания резервированные), РИП (резервированные источники питания) как правило обеспечивают подачу электроэнергии на одно или несколько устройств или систем. Эти источники имеют как правило мощность до 500 Вт и обеспечивают необходимые выходные напряжения.
Сегодня производители выпускают три типа ИБП. Каждый из них обладает своими тонкостями эксплуатации. Главным элементом конструкции этих приборов является аккумуляторная батарея. В конструкции применяют свинцово-кислотные аккумуляторы, которые имеют следующие характеристики – емкость равная 7 или 9 Ач, напряжение 12 Вольт. В простых конструкциях применяют один аккумулятор, в более сложных устройствах может быть использовано несколько батарей сразу.
ИБП резервного класса. ИБП этого класса, относят к самым простым. Это устройство работает по очень простому принципу – питание потребителей осуществляется через электрическую сеть, если питание пропадает, то оно начинает поступать от АКБ, являющихся неотъемлемой частью устройства. Зарядку аккумуляторов происходит при работе устройства от сети. Статистика говорит о том, что эффективность таких приборов лежит в диапазоне от 55 до 60%. Большая часть приборов этого класса работают по описанной технологии, но так сложилось, что обеспечивают предельно низкий уровень защиты. Очистка сигнала от помех осуществляется только частично.
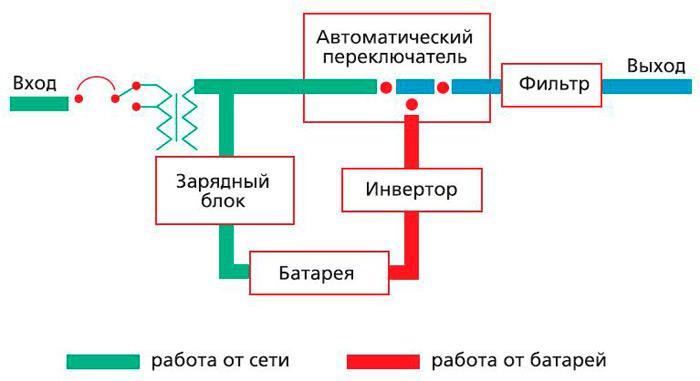
ИБП линейно-интерактивного типа. Работа этих приборов сходна с изделиями резервного типа. Различие заключено в следующем – блоки питания линейного типа обладают возможностью стабилизирования напряжения, проводимого при содействии коммутирующего устройства. Достоинство этого метода заключается в том, что отсутствует нужда в переключения питания при возникновении изменений параметров напряжения. Оно может достигать до 20 % от номинала. При этом напряжение на выходе не изменяется. Результативность защиты блоков питания этого класса достигает 85%. Работа бесперебойных условий можно разделить на две группы. Устройства, которые относят к первому классу, выдают на выходе ступенчатую синусоиду. Приборы, которые относят ко второму классу, генерируют качественную синусоиду, без изменений. Ее наличие позволяет обеспечить защиту таких устройств как электрических двигателей и отопительного оборудования.
ИБП Онлайн типа. Это один из самых надежных и высоко технологичных приборов. Они работают на основании технологии двойного изменения тока. На сегодня это самая из совершенная технологий. Уровень защиты у такого устройства достигает 100 %, причем независимо от того, работает оно от батарей или от сети питания. Как работает устройство этого типа – на входе в устройство ток трансформируется в постоянный. После этого происходит обратная трансформация. То есть, только что полученный постоянный ток, преобразуется в переменный. Полученный ток обладает высокими характеристиками и по синусоиде напряжения, и по его значению.
IT-специалисты, не вникая в суть проблемы, ежедневно пытаются добиться высокой отказоустойчивости, покупая все новое дорогостоящее аппаратное и программное обеспечение. Многие из них полагают, что для достижения высокой отказоустойчивости существует некое готовое технологическое решение, которое можно применить, а потом раз и навсегда забыть о проблеме. Однако технология - лишь малая часть мер обеспечения высокой отказоустойчивости. Настоящая высокая отказоустойчивость достигается комплексным воздействием специалистов, подходов и технологий. Хотя строить решения высокой отказоустойчивости можно и без одного из этих компонентов, внимание ко всем трем позволяет обеспечить полномасштабной отказоустойчивостью всю информационную систему предприятия целиком. Без специалистов на местах, управляющих процессами, но при наличии подхода, гарантирующего, что системы останутся отказоустойчивыми, технология будет не в состоянии решить задачу.
